[IsaacLab Part 3] 강화학습으로 Go2 걷게하기
Isaac Lab manager-based 환경과 RSL-RL 프레임워크로 Unitree Go2 walking policy를 학습하는 흐름을 정리한다.

[IsaacLab Part 3] 강화학습으로 Go2 걷게하기
Isaac sim에서 강화학습을 통해 얻은 모델로 로봇을 걷게하려면 RL 학습시와 동일한 config (observation, Policy, Actions)를 유지해야 합니다.
따라서 오늘은 Isaac Lab의 “manager-based” 환경 프레임워크와 RSL-RL 학습프레임워크를 통해 unitree go2모델의 강화학습 환경을 구성해 보겠습니다.
RSL-RL 학습 프레임워크란?
RSL-RL 은 ETH Zurich의 Robotic Systems Lab(RSL)에서 개발한 고성능 강화학습 라이브러리입니다. 주로 PPO(Proximal Policy Optimization) 알고리즘을 구현하며, 다음과 같은 특징이 있습니다.
Isaaclab Code
~/isaaclab/scripts/reinforcement_learning/rsl_rl/train.py
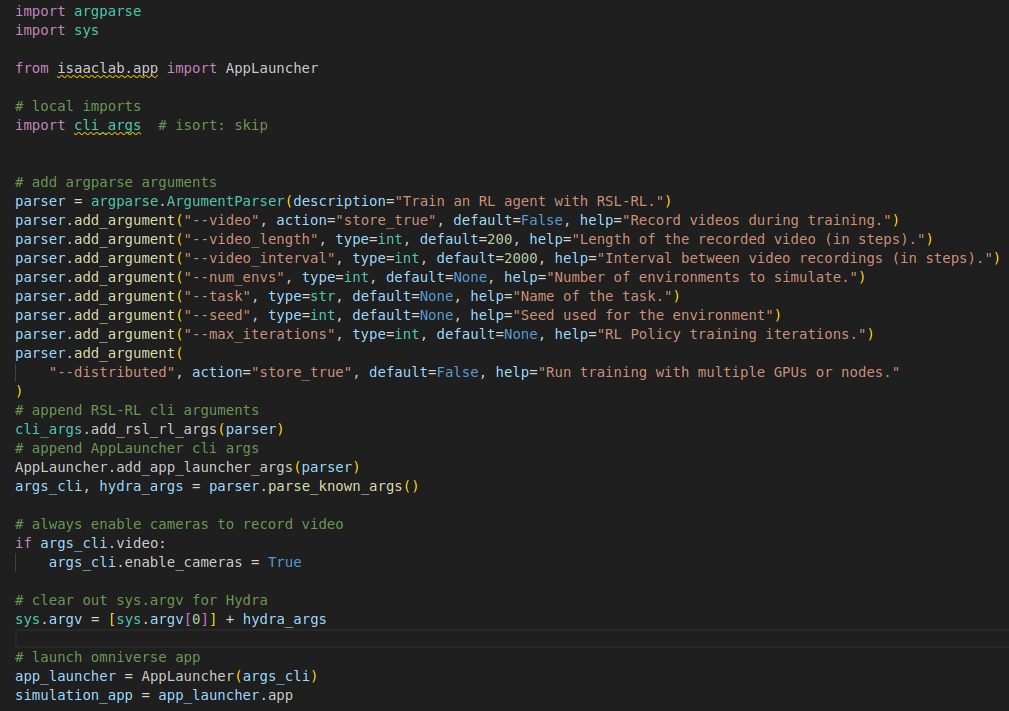
- args
- –video : 학습과정에서 video를 녹화할것인지에 대한 설정
- –num_denvs : 병렬 시뮬레이션 환경 개수 (보통 수천 개 설정 가능)
- –distributed : 멀티 GPU를 사용하여 학습속도 가속
- –resume : 이전 학습 지점부터 이어서 학습
- 시뮬레이터 초기화
- Isaac Sim은 일반적인 Python 라이브러리와 달리, 엔진 자체를 먼저 런칭해야 합니다. args_parser를 통해 headless, gpu설정 등을 결정한 후 시뮬레이션을 실행합니다.
1
2
3
4
from isaaclab.app import AppLauncher
# ... (중략) ...
app_launcher = AppLauncher(args_cli)
simulation_app = app_launcher.app
main 함수
하이퍼 파라미터 설정 및 업데이트
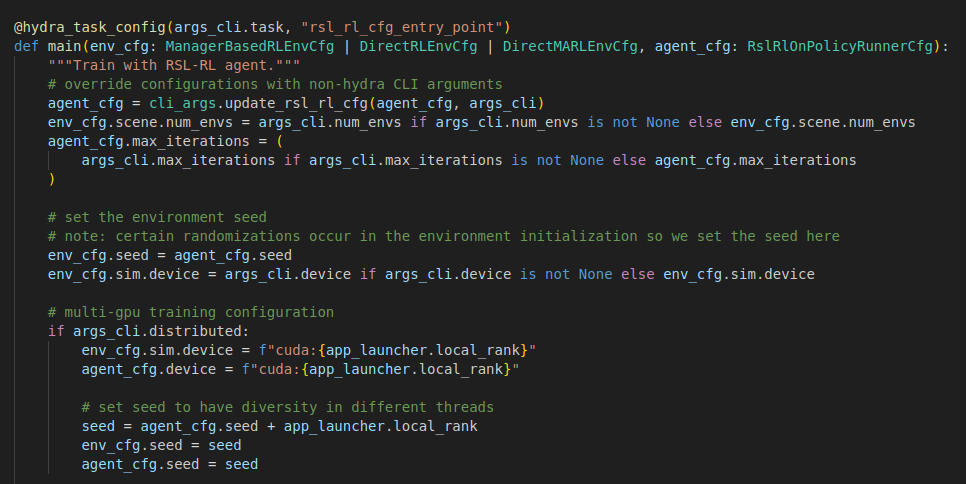
- Hydra를 통한 설정 매핑
- 사용자가 cli를 통해 –task Isaac-Velocity-Flat-Unitree-Go2-v0\ 라고 입력해주면 hydra는 해당 테스크에 매핑된 yaml파일을 읽어옵니다.
- 읽어온 yaml 파일의 숫자와 문자열을 main함수의 인자인 env_cfg, agent_cfg의 ManagerBasedRLEnvCfg와 RslRlOnPolicyRunnerCfg로 자동 주입합니다.
- Cli설정 우선
- num_envs와 max_iterations와 같은 설정은 yaml파일에 있는 값보다 사용자가 입력한 설정을 우선적으로 적용합니다.
환경의 인스턴스화

- OpenAi Gym 형식을 사용하여 환경을 만듭니다. env_cfg에 정의된 로봇과 배경요소들이 Isaac Sim 월드에 실제로 배치 됩니다.
- 멀티 에이전트 환경 (로봇이 여러대인 환경)인지 체크한 후 Multi_agent의 환경 관측값들을 하나의 관측값으로 이어 붙여 버립니다. 이러한 과정을 통해 단일 에이전트 학습 에 기반하여 설계된 Rsl_rl 에서 학습을 진행할 수 있습니다.
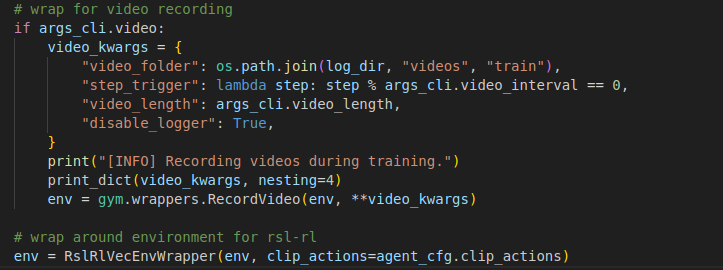
- RslRlVecEnvWrapper: 이 스크립트에서 가장 중요한 부분 중 하나입니다. Isaac Lab 환경에서 나오는 관측값(Observation) 텐서를 RSL-RL 라이브러리가 요구하는 특정 텐서 구조와 장치(Device) 위치로 변환해주는 역할을 합니다.
강화학습 시작
- OnPolicyRunner: PPO 알고리즘의 루프를 돌리는 주체입니다. runner.learn()이 호출되면 지정된 반복 횟수(max_iterations)만큼 다음 과정을 반복합니다:
- 현재 정책으로 로봇 움직이기 (Rollout)
- 데이터 수집 및 보상 계산
- 신경망 가중치 업데이트 (Optimization)
- 로그 기록 및 체크포인트 저장
Configclass
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import gymnasium as gym
from . import agents
##
# Register Gym environments.
##
gym.register(
id="Isaac-Velocity-Flat-Unitree-Go2-v0",
entry_point="isaaclab.envs:ManagerBasedRLEnv",
disable_env_checker=True,
kwargs={
"env_cfg_entry_point": f"{__name__}.flat_env_cfg:UnitreeGo2FlatEnvCfg",
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:UnitreeGo2FlatPPORunnerCfg",
"skrl_cfg_entry_point": f"{agents.__name__}:skrl_flat_ppo_cfg.yaml",
},
)
- ~/isaaclab/source/isaaclab_tasks/isaaclab_tasks/manager_based/locomotion/velocity/config/go2/init.py 에 hydra에서 참조하는 gym환경의 ID와 각 cfg파일의 경로가 담겨있습니다.
rsl_rl_ppo_cfg.py
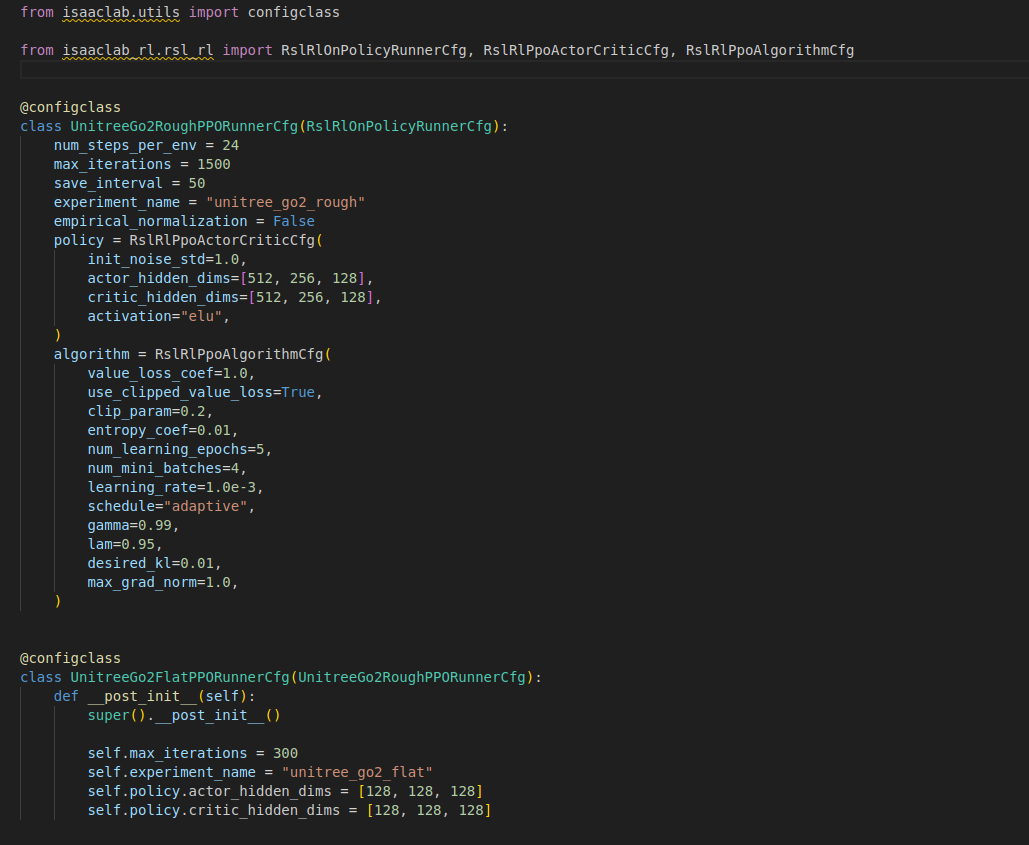
- UnitreeGo2RoughPPORunnerCfg : RslRlOnPolicyRunnerCfg를 계승하는 class로써 ActorCritic Policy를 가지고 batch, lr등의 학습 파라미터를 설정합니다. onPolicy는 하나의 환경데이터를 얻고 조금씩 정책을 업데이트 하는 학습법을 말합니다.
rough_env_cfg.py
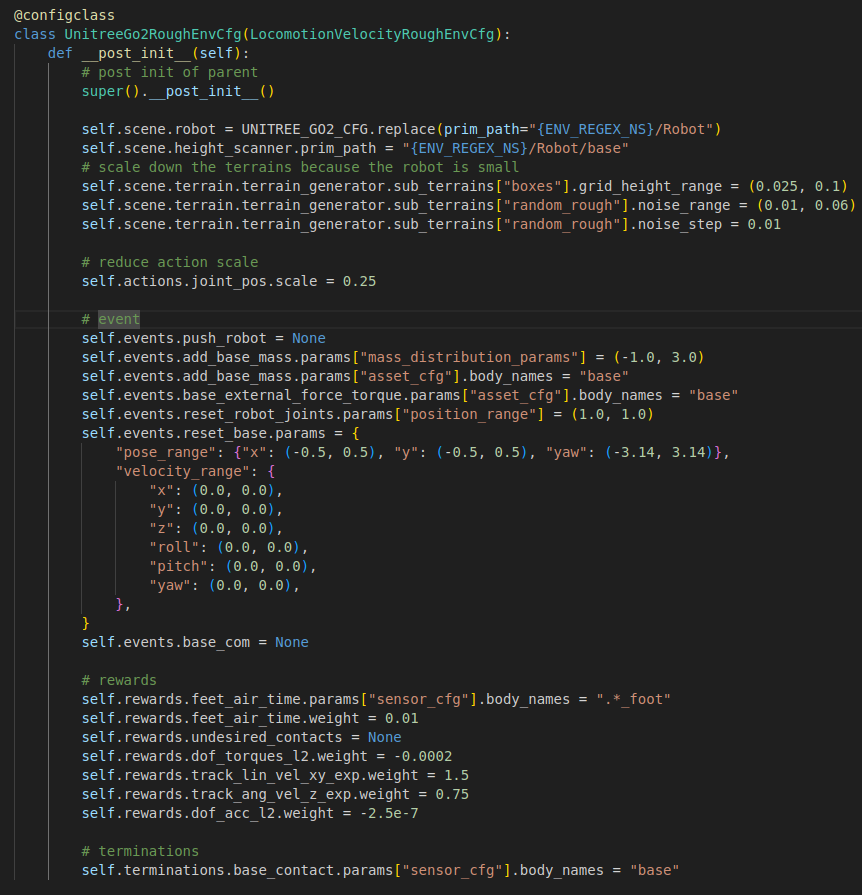
- go2를 UNITREE_GO2_CFG설정 파일로 생성합니다. 이후 height scanner와 event, acions, reward, termination과 같은 조건을 설정해줍니다.
RL 학습
1
2
./isaaclab.sh -p scripts/reinforcement_learning/rsl_rl/train.py --task Isaac-Velocity-Rough-Unitree-
Go2-v0 --num_envs 4096 --max_iterations 10000 --video --headless
- 위의 script를 통해 학습을 하여 로봇의 running policy를 학습 시킬 수 있게 됩니다.
결과물
9000 iteration까지 학습했을때의 결과물 입니다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.