[Unitree Go2 part 3] Reward 수정과 Real Gap
reward 수정으로 MuJoCo 보행은 개선되었지만, 실제 Go2 deploy에서 다시 드러난 real gap과 torque 문제를 정리한다.
1. 현재 상황
발을 들도록 유도하는 reward를 여러 방식으로 추가한 결과, 이제는 MuJoCo에서는 Go2가 걸을 수 있게 되었습니다.
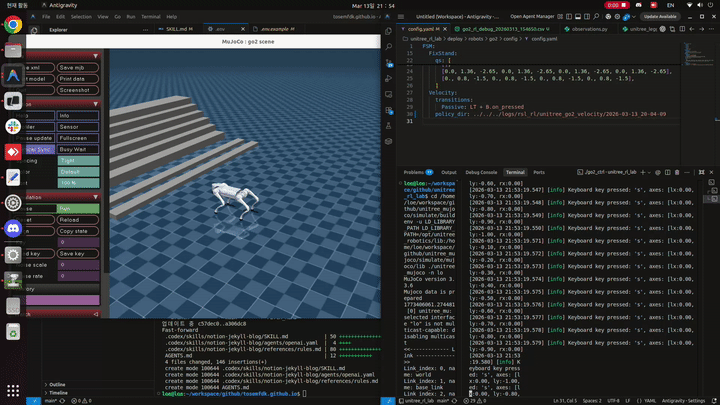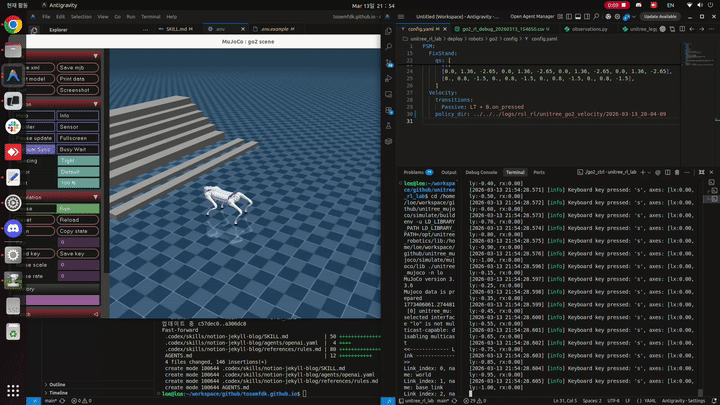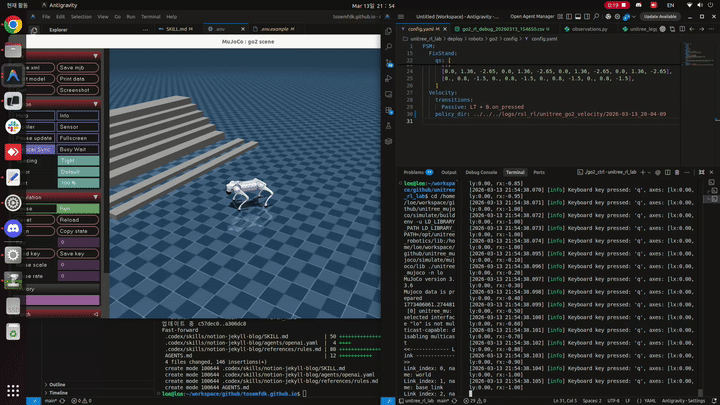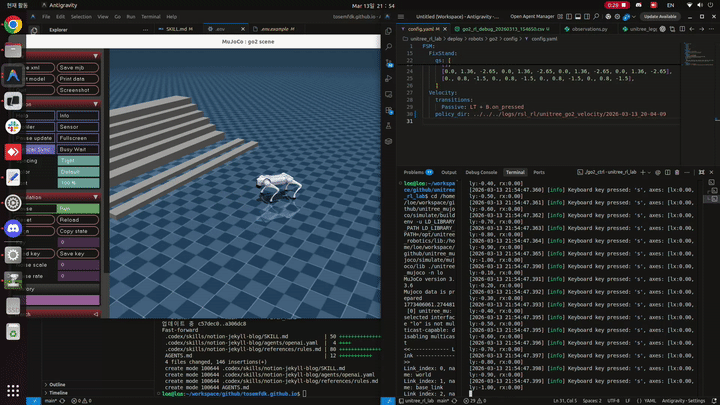
이번에 사용한 reward는 크게 세 가지였습니다.
feet_air_time: 발을 threshold보다 오래 들었을 때 보상을 주는 항입니다.- weight를
0.01에서5.0으로 변경했습니다.
- weight를
feet_clearance: height scanner를 기준으로 발을 target height만큼 들어 올렸을 때 보상을 주는 항입니다.- 움직이는 발의 x, y 좌표에서 가장 가까운 height scanner 값을 기준으로 비교했고, target height는
0.08 m로 설정했습니다.
feet_clearance_reward()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
def feet_clearance_reward( env: ManagerBasedRLEnv, asset_cfg: SceneEntityCfg, sensor_cfg: SceneEntityCfg, target_height: float, std: float, tanh_mult: float, ) -> torch.Tensor: """Signed foot-clearance reward from local terrain height. Positive when swing-foot clearance is above target, negative when below. """ asset: RigidObject = env.scene[asset_cfg.name] height_scanner = env.scene.sensors[sensor_cfg.name] # Foot positions in world frame foot_pos = asset.data.body_pos_w[:, asset_cfg.body_ids] foot_xy = foot_pos[:, :, :2] foot_z = foot_pos[:, :, 2] # Height scanner hit points in world frame hit_xy = height_scanner.data.ray_hits_w[:, :, :2] hit_z = height_scanner.data.ray_hits_w[:, :, 2] # For each foot, pick the closest ray-hit point in XY and use its Z value as local ground height. hit_dist_sq = torch.sum((foot_xy.unsqueeze(2) - hit_xy.unsqueeze(1)) ** 2, dim=-1) invalid_hit = torch.isinf(hit_z) | torch.isinf(hit_xy).any(dim=-1) hit_dist_sq = torch.where(invalid_hit.unsqueeze(1), torch.full_like(hit_dist_sq, float("inf")), hit_dist_sq) closest_hit_idx = torch.argmin(hit_dist_sq, dim=2) ground_z = torch.gather(hit_z, 1, closest_hit_idx) ground_z = torch.where(torch.isfinite(ground_z), ground_z, foot_z) # Signed clearance around target height: # > 0 when above target, < 0 when below target. clearance = (foot_z - ground_z) - target_height clearance_scaled = torch.tanh(clearance / max(std, 1e-6)) foot_velocity_tanh = torch.tanh(tanh_mult * torch.norm(asset.data.body_lin_vel_w[:, asset_cfg.body_ids, :2], dim=2)) reward = torch.mean(clearance_scaled * foot_velocity_tanh, dim=1) reward *= torch.linalg.norm(env.command_manager.get_command("base_velocity"), dim=1) > 0.1 reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7 return reward
- 움직이는 발의 x, y 좌표에서 가장 가까운 height scanner 값을 기준으로 비교했고, target height는
feet_body_height: base frame을 기준으로 발이 특정 높이까지 올라오도록 유도하는 항입니다.- Go2의 default pose에서 body height가 약 35 cm이므로, 지면으로부터 약 8 cm를 목표로 잡아 target height를
-0.27로 설정했습니다.
feet_height_body()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
def feet_height_body( env: ManagerBasedRLEnv, command_name: str, asset_cfg: SceneEntityCfg, target_height: float, tanh_mult: float, ) -> torch.Tensor: """Reward the swinging feet for clearing a specified height off the ground""" asset: RigidObject = env.scene[asset_cfg.name] cur_footpos_translated = asset.data.body_pos_w[:, asset_cfg.body_ids, :] - asset.data.root_pos_w[:, :].unsqueeze(1) footpos_in_body_frame = torch.zeros(env.num_envs, len(asset_cfg.body_ids), 3, device=env.device) cur_footvel_translated = asset.data.body_lin_vel_w[:, asset_cfg.body_ids, :] - asset.data.root_lin_vel_w[ :, : ].unsqueeze(1) footvel_in_body_frame = torch.zeros(env.num_envs, len(asset_cfg.body_ids), 3, device=env.device) for i in range(len(asset_cfg.body_ids)): footpos_in_body_frame[:, i, :] = quat_apply_inverse(asset.data.root_quat_w, cur_footpos_translated[:, i, :]) footvel_in_body_frame[:, i, :] = quat_apply_inverse(asset.data.root_quat_w, cur_footvel_translated[:, i, :]) foot_z_target_error = torch.square(footpos_in_body_frame[:, :, 2] - target_height).view(env.num_envs, -1) foot_velocity_tanh = torch.tanh(tanh_mult * torch.norm(footvel_in_body_frame[:, :, :2], dim=2)) reward = torch.sum(foot_z_target_error * foot_velocity_tanh, dim=1) reward *= torch.linalg.norm(env.command_manager.get_command(command_name), dim=1) > 0.1 reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7 return reward
2. Simulation에서 확인한 문제
- Go2의 default pose에서 body height가 약 35 cm이므로, 지면으로부터 약 8 cm를 목표로 잡아 target height를
reward를 추가하면서 simulation에서는 분명히 개선이 있었습니다. 하지만 reward를 강하게 줄수록 policy가 의도하지 않은 방식으로 보상을 최적화하는 모습도 보였습니다.
2.1 Reward 민감도
- Go2는
feet_slideweight에 상당히 민감하게 반응했습니다. penalty를 과하게 키우면 오히려 발을 떼지 않는 문제가 생겼습니다. - 이를 보완하기 위해
feet_body_heightreward를 설계했습니다.- 하지만 target height를 높게 설정하는 순간, robot이 발을 드는 대신 base height를 낮추는 문제가 발생했습니다.
- 하지만 target height를 높게 설정하는 순간, robot이 발을 드는 대신 base height를 낮추는 문제가 발생했습니다.
feet_clearancereward에서 target height를0.08 m로 두고 학습하자, 발을 옆으로 들어air_time과clearancereward를 동시에 키우려는 local minimum이 나타났습니다.
이 단계에서는 feet_air_time을 빼고 feet_clearance 중심으로 학습하는 방향을 선택했습니다.
2.2 feet_clearance reward 확인
![]()
![]()
3. Real Deploy 결과
다양한 모델을 학습한 뒤 실제 로봇에 deploy했지만, 결과는 아직 충분하지 않았습니다. 이전과 마찬가지로 앞뒤좌우 command에 따라 몸을 기울이기만 할 뿐, 발을 제대로 드는 동작은 거의 보이지 않았습니다.

또한 로봇이 stand 상태에서 다리를 많이 접는 현상이 있었습니다. 이 문제는 last_action observation 구성 버그와 관련이 있었습니다.
last_action에는 ONNX 모델의 raw action이 들어가야 했지만, deploy 코드에서는 scale과 offset이 적용된 target position에 가까운 값이 들어가고 있었습니다. 이 때문에 policy가 training 때와 다른 형태의 action history를 보고 있었고, 이전 action이 지나치게 보수적으로 들어가는 문제가 생겼습니다. 이 부분을 수정하자 로봇 다리가 펴지는 것을 확인할 수 있었습니다.

4. Torque 관점에서 본 문제
Go2에 deploy된 모델의 torque 값을 확인해보니, 뒷다리 torque가 앞다리에 비해 비정상적으로 낮게 나오는 것을 확인했습니다.
가능한 원인은 두 가지로 봤습니다.
- terrain height를 너무 높게 잡아, 앞발이 Go2 전체를 끌어가는 형태로 학습되었을 수 있습니다.
- position error 기반의 PD target만으로는 Go2가 실제로 필요한 torque를 만들기 어려웠을 수 있습니다.
deploy 시 뒷다리 stiffness를 25에서 40으로 변경하자, 로봇이 앞뒤좌우로 조금씩 걷기 시작했습니다.


5. 남은 문제
- 앞뒤로 움직일 때 다리를 너무 높게 드는 문제가 있었습니다.
- 뒷다리 stiffness를 임의로 높이면서 torque가 강하게 나왔고, 그 결과 앞다리에 비해 뒷다리가 과하게 올라갔습니다. 이는 Go2의 balance를 무너뜨려 안정적인 제어를 어렵게 만들었습니다.
- command를
0.5 m/s이상으로 줘야만 로봇이 움직이기 시작했습니다.- 실제로 움직이기 위해 필요한 torque margin이 높다는 뜻입니다.
6. 다음 방향
이 시점에서 reward 조정만으로는 부족하다고 판단했습니다. simulation에서는 통과하지만 real에서는 torque가 부족하거나 target tracking이 흔들리는 문제가 남아 있었기 때문입니다.
다음 글에서는 이 문제를 줄이기 위해 feed-forward torque를 추가하는 방향을 실험합니다.
- 기존 구조에서는 로봇이 자기 몸무게를 버티기 위해 policy가 목표 관절 각도를 크게 틀어야 했습니다. simulation에서는 이런 방식이 어느 정도 통했지만, real robot에서는 actuator가 그 target을 안정적으로 따라가지 못했습니다.
- PhysX에서 계산한 gravity compensation torque를 사용해, 현재 자세에서 중력을 버티는 데 필요한 기본 torque를 feed-forward로 먼저 넣어봅니다.
- 기대한 효과는 policy가 몸을 억지로 띄우기 위한 과격한 target 대신, 더 부드러운 발 궤적을 출력하도록 만드는 것입니다.