2. Bellman Equation
벨만 방정식이 필요한 이유와 가치 함수, 최적 정책, Known MDP와 Unknown MDP의 차이를 정리한다.
0. 벨만 방정식이 필요한 이유
이전 글에서 MDP의 목표는 장기적인 반환값(Return)을 최대화하는 최적 정책을 찾는 것이라고 정리했습니다. 문제는 이 목표가 말처럼 간단하지 않다는 점입니다.
강화학습에서 미래 보상을 계산하려고 하면 크게 두 가지 어려움이 생깁니다.
- 지연된 보상 (Delayed Reward): 지금 당장 좋은 행동이 미래에는 나쁜 결과로 이어질 수 있고, 반대로 지금은 손해인 듯한 행동이 나중에 엄청난 보상을 가져올 수도 있습니다.
- 무한한 경우의 수: 앞으로 일어날 모든 상태와 행동의 조합을 끝까지 계산해서 어떤 선택이 좋은지 판단하는 것은 현실적으로 불가능합니다.
그렇다면 에이전트는 어떻게 ‘미래’를 보고 최적의 결정을 내릴 수 있을까요?
이 문제를 풀기 위한 핵심 도구가 바로 벨만 방정식(Bellman Equation)입니다.
벨만 방정식의 핵심 아이디어는 이것입니다.
미래 전체를 한 번에 계산하지 말고, 현재 보상 + 다음 상태의 가치로 현재 상태의 가치를 재귀적으로 표현하자.
이 아이디어가 중요한 이유는 두 가지입니다.
- 긴 미래를 한 단계 문제로 바꿉니다. 에이전트는 모든 미래를 직접 펼쳐볼 필요 없이, 다음 상태 $s^{\prime}$의 가치 $v(s^{\prime})$를 이용해 현재 상태의 가치를 계산할 수 있습니다.
- 미래의 가치를 현재로 가져옵니다. 다음 상태의 가치를 현재 상태에 반영하는 과정을 백업(Backup)이라고 부릅니다. 이 덕분에 먼 미래의 보상도 현재 선택의 평가에 들어올 수 있습니다.
정리하면, 벨만 방정식은 미래 보상의 총합이라는 어려운 문제를 현재 보상과 다음 상태 가치의 관계로 바꿔주는 재귀식입니다.
1. 가치 함수 (Value Function)
가치 함수는 현재 상태 또는 행동이 장기적으로 얼마나 좋은지를 나타내는 함수입니다. 여기서 좋다는 것은 앞으로 얻을 반환값의 기대값이 크다는 뜻입니다.
모든 가치 함수는 특정 정책($\pi$)을 기준으로 정의됩니다. 같은 상태라도 어떤 정책을 따르느냐에 따라 앞으로 받을 보상이 달라지기 때문입니다.
1.1 상태 가치 함수 (State-Value Function, $v_\pi(s)$)
상태 가치 함수는 특정 상태 $s$의 가치를 평가합니다.
- 의미: 상태 $s$에서 시작하여, 앞으로 정책 $\pi$를 계속 따랐을 때 받을 것이라 예상되는 총 미래 보상의 합
- 답하는 질문: 정책 $\pi$를 따를 때, 이 상태에 있는 것이 얼마나 좋은가?
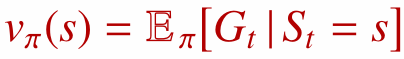
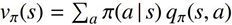
1.2 행동 가치 함수 (Action-Value Function, $q_\pi(s, a)$)
행동 가치 함수는 특정 상태 $s$에서 특정 행동 $a$를 선택하는 것의 가치를 평가합니다.
- 의미: 상태 $s$에서 행동 $a$를 한 뒤, 그 이후부터 정책 $\pi$를 계속 따랐을 때 예상되는 총 미래 보상의 합
- 답하는 질문: 정책 $\pi$를 따를 때, 이 상태에서 이 행동을 하는 것이 얼마나 좋은가?

1.3 왜 $q$ 함수가 중요할까?
$v(s)$가 상태 자체의 좋음을 알려준다면, $q(s, a)$는 그 상태에서 특정 행동을 선택하는 것의 좋음을 알려줍니다.
이 차이는 환경 모델을 모를 때 특히 중요합니다. $q(s, a)$를 알고 있다면, 상태 $s$에서 가능한 행동들의 $q$ 값을 비교해서 가장 좋은 행동을 바로 선택할 수 있습니다. 반면 $v(s)$만 알고 있다면 각 행동이 어떤 다음 상태로 이어지는지, 즉 환경 모델이 추가로 필요합니다.
1.4 가치 함수의 수학적 근거
가치 함수의 핵심 아이디어는 현재 상태의 가치를 다음 상태 가치들의 기댓값으로 표현할 수 있다는 것입니다. 이 재귀적 관계는 두 가지 개념과 연결됩니다.
- 전체 확률의 법칙 (Law of Total Probability): 가능한 다음 상태들을 모두 고려하고, 각 상태로 이동할 확률만큼 가중해서 현재 가치를 계산합니다.
- 큰 수의 법칙 (Law of Large Numbers): 환경 모델을 몰라도 충분히 많은 경험을 평균내면, 실제 기대값에 가까워질 수 있다는 학습의 근거가 됩니다.
이 두 관점 덕분에 우리는 환경을 알고 있을 때는 계산으로, 모를 때는 경험으로 가치 함수를 추정할 수 있습니다.
2. 벨만 기대 방정식 (Bellman Expectation Equation)
벨만 기대 방정식은 현재 정책($\pi$)을 따랐을 때의 가치를 계산합니다. 즉, 지금 가진 정책을 그대로 따른다면 각 상태와 행동이 얼마나 가치 있는지를 평가하는 식입니다.
핵심은 현재 정책에 따라 행동했을 때 얻는 보상과 다음 상태 가치의 기댓값을 더하는 것입니다. 그래서 벨만 기대 방정식은 정책 평가(Policy Evaluation)의 기본 도구가 됩니다.
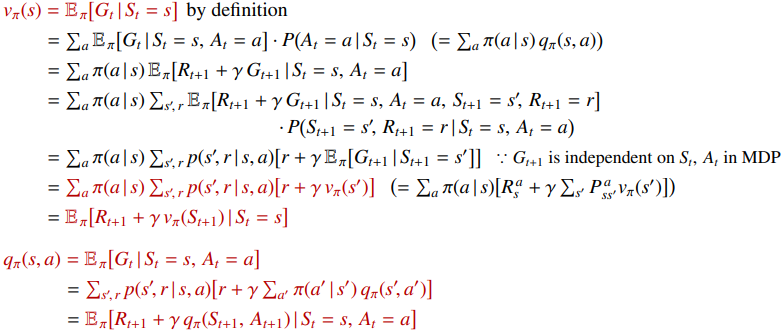
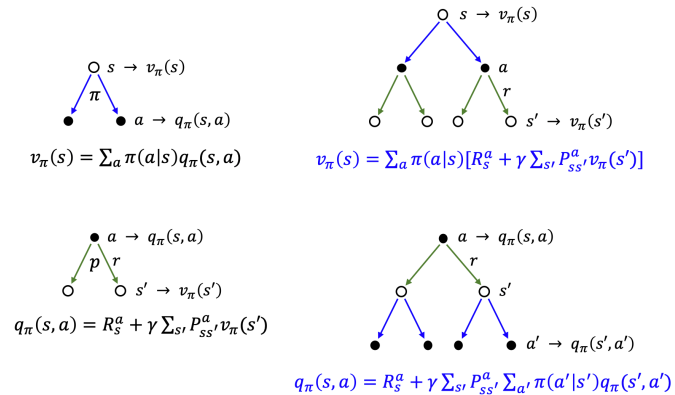
이 방정식은 현재와 미래의 가치를 연결합니다. 덕분에 현재 정책의 가치를 한 번에 계산하는 대신, 반복적인 백업을 통해 점진적으로 구할 수 있습니다.
3. 최적 가치 함수와 최적 정책 (Optimal Value Function & Policy)
모든 정책($\pi$)에는 그 정책에 대응되는 가치 함수($v_\pi$, $q_\pi$)가 존재합니다. 그중에서 가장 큰 기대 반환값을 만들어내는 정책을 최적 정책($\pi^{\ast}$)이라고 합니다.
최적 정책을 따랐을 때의 가치 함수를 최적 가치 함수라고 부릅니다.
- 최적 상태 가치 함수($v^{\ast}(s)$): 상태 $s$에서 시작했을 때 얻을 수 있는 최대 기대 반환값입니다.
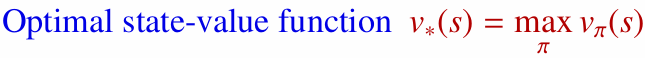
- 최적 행동 가치 함수($q^{\ast}(s, a)$): 상태 $s$에서 행동 $a$를 한 뒤 얻을 수 있는 최대 기대 반환값입니다.
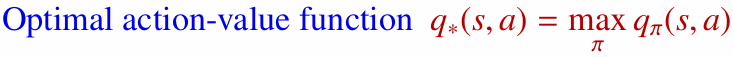
특히 $q^{\ast}(s, a)$를 알면 현재 상태에서 어떤 행동을 선택해야 하는지 바로 비교할 수 있습니다. 그래서 많은 Model-Free 강화학습 알고리즘은 최적 행동 가치 함수에 가까운 값을 학습하려고 합니다.

이 정리는 강화학습에서 최적해를 찾을 수 있다는 이론적 기반을 제공합니다. 목표로 삼을 최적 가치 함수와 최적 정책이 존재하기 때문에, 이후 알고리즘들은 이 값을 계산하거나 추정하는 방향으로 설계됩니다.
3.1 최적 정책을 찾는 방법
최적 행동 가치 함수가 주어졌다면 최적 정책은 간단히 찾을 수 있습니다. 각 상태에서 $q^{\ast}(s, a)$가 가장 큰 행동을 선택하면 됩니다.
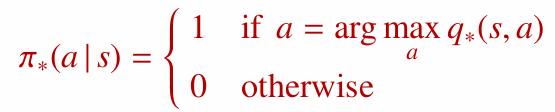
이때 만들어지는 정책은 상태 $s$에서 최적 행동만 확률 1로 선택하고, 나머지 행동은 확률 0으로 선택하는 결정적(deterministic) 정책입니다.
- 어떤 MDP에서도 항상 결정적 최적 정책(deterministic optimal policy)이 존재합니다.
- 만약 우리가 $q^{\ast}(s, a)$를 찾는다면, 최적 정책 $\pi^{\ast}(s) = \arg\max_a q^{\ast}(s, a)$도 함께 얻을 수 있습니다.
- Unknown MDP(Model-Free)에서는 환경 모델이 없기 때문에, 경험 샘플을 이용해 $q^{\ast}(s, a)$에 가까운 Q값을 직접 추정합니다.
3.2 최적 정책의 특징: 벨만 최적 방정식
최적 정책($\pi^{\ast}$)은 최적 가치 함수($v^{\ast}$와 $q^{\ast}$)를 만족합니다. 이때 사용하는 식이 벨만 최적 방정식(Bellman Optimality Equation)입니다.
벨만 기대 방정식이 현재 정책을 따르는 평균을 계산했다면, 벨만 최적 방정식은 가능한 행동 중 가장 좋은 행동의 최댓값(max)을 사용합니다.
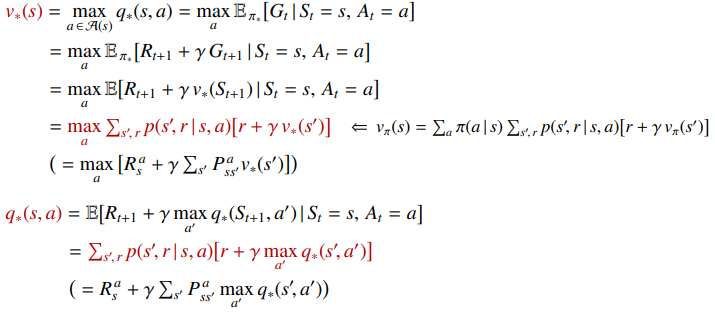
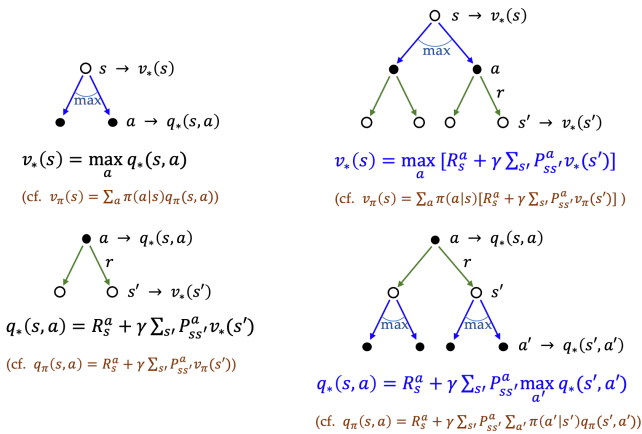
이 방정식을 풀면 최적 가치 함수를 얻을 수 있고, 그로부터 최적 정책을 만들 수 있습니다.
3.3 $v^{\ast}$와 $q^{\ast}$ 중 무엇을 알아야 할까?
State-Value ($v^{\ast}$)만으로는 부족한 이유
최적 상태 가치 함수($v^{\ast}$)만 알고 있으면 각 상태가 얼마나 좋은지는 알 수 있습니다. 하지만 현재 상태에서 어떤 행동을 해야 그 좋은 상태로 갈 수 있는지는 바로 알 수 없습니다.
최적 행동을 찾으려면 가능한 모든 행동에 대해 다음 상태 $s^{\prime}$와 그 상태의 가치 $v^{\ast}(s^{\prime})$를 비교해야 합니다. 이 과정에는 상태 변환 확률 $P(s^{\prime} \mid s, a)$, 즉 환경 모델이 필요합니다.
Action-Value ($q^{\ast}$)의 강력함
반대로 최적 행동 가치 함수($q^{\ast}$)를 알고 있다면 상황이 훨씬 단순해집니다. $q^{\ast}(s, a)$는 상태 $s$에서 행동 $a$를 선택하는 것의 가치를 직접 알려줍니다. 따라서 환경 모델을 따로 알지 못해도, 현재 상태에서 $q^{\ast}(s, a)$가 가장 큰 행동을 고르면 됩니다.
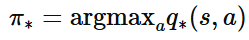
이것이 환경을 모르는 대부분의 Model-Free 강화학습에서 $q^{\ast}$ 또는 그 근사값이 중요한 이유입니다.
4. Known MDP vs. Unknown MDP
결국 벨만 방정식을 푸는 접근법은 우리가 환경에 대해 아는 정도에 따라 두 가지로 나뉩니다.
- Known MDP: 상태 변환 확률 $P$와 보상 함수 $R$을 알고 있는 상황입니다. 이 경우에는 벨만 방정식을 이용해 가치 함수와 정책을 계산할 수 있고, 이런 접근을 계획(Planning)이라고 부릅니다. DP(Dynamic Programming)가 여기에 해당합니다.
- Unknown MDP: 환경의 규칙을 모르는 상황입니다. 이 경우에는 에이전트가 직접 환경과 상호작용하며 얻은 경험으로 가치 함수나 정책을 추정해야 하고, 이런 접근을 학습(Learning)이라고 부릅니다. 대부분의 강화학습 문제가 여기에 가깝습니다.
즉, 벨만 방정식은 환경을 알고 있을 때는 계산의 기준이 되고, 환경을 모를 때는 학습 목표의 기준이 됩니다.
5. 정리하며: 다음 단계로
이번 글에서는 MDP를 실제로 풀기 위한 핵심 도구인 벨만 방정식을 정리했습니다.
- 벨만 방정식은 현재 가치를 현재 보상 + 다음 상태 가치로 표현합니다.
- 벨만 기대 방정식은 주어진 정책의 가치를 평가합니다.
- 벨만 최적 방정식은 최적 가치 함수와 최적 정책을 찾기 위한 기준이 됩니다.
- Known MDP에서는 계획을 통해 값을 계산하고, Unknown MDP에서는 경험을 통해 값을 학습합니다.
다음 글에서는 환경 모델을 알고 있는 Known MDP 상황에서 벨만 방정식을 이용해 최적 정책을 계산하는 방법, 즉 동적 계획법(Dynamic Programming)을 살펴보겠습니다.