1. MDP (Markov Decision Process)
강화학습의 뼈대가 되는 MDP의 구성 요소, 마르코프 속성, 최적 정책의 의미를 정리한다.
0. MDP의 전체 그림: 에이전트와 환경의 상호작용
MDP를 하나씩 뜯어보기 전에, 강화학습이 어떤 구조로 굴러가는지 먼저 잡고 가겠습니다. 강화학습은 기본적으로 에이전트(Agent)와 환경(Environment)이 반복해서 상호작용하는 루프입니다.
- 에이전트는 현재 상태(State, $S_t$)를 관찰합니다.
- 에이전트는 정책($\pi$)에 따라 행동(Action, $A_t$)을 결정합니다.
- 환경은 그 행동의 결과로 보상(Reward, $R_{t+1}$)과 다음 상태(State, $S_{t+1}$)를 돌려줍니다.
- 에이전트는 이 과정을 반복하면서 더 큰 장기 보상을 얻는 방향으로 정책을 개선합니다.
이 루프를 수학적으로 다루기 위한 기본 틀이 바로 MDP(Markov Decision Process)입니다.
1. 마르코프 속성 (MP)
MDP를 이해하려면 먼저 마르코프 속성(Markov Property, MP)을 알아야 합니다. 이름은 조금 딱딱하지만, 핵심은 꽤 단순합니다.
마르코프 속성(MP)이란?
현재 상태($S_t$)가 주어졌을 때, 다음 상태($S_{t+1}$)는 오직 현재 상태($S_t$)에만 의존하고, 과거의 모든 이력($S_1, …, S_{t-1}$)과는 무관하다는 성질입니다.
쉽게 말하면, 미래를 예측하는 데 필요한 정보가 현재 상태 안에 충분히 담겨 있다는 뜻입니다.
체스를 예로 들어보면, 지금 내 앞에 놓인 체스판의 말 배치가 바로 현재 상태입니다. 다음 수를 결정할 때 중요한 것은 현재 판세이지, 10수 전에 말이 어디 있었는지가 아닙니다. 과거의 정보가 현재 판세에 이미 반영되어 있다고 보는 것입니다.
수식으로는 보통 이렇게 표현합니다.
\[P(S_{t+1} \mid S_t) = P(S_{t+1} \mid S_1, S_2, ..., S_t)\]이 성질 덕분에 에이전트는 과거의 모든 기록을 들고 다니지 않아도 됩니다. 매 순간 현재 상태만 잘 정의되어 있다면, 그 상태를 기준으로 다음 행동을 결정할 수 있습니다.
2. MDP의 핵심 구성 요소
MDP는 마르코프 속성을 만족하는 환경에 에이전트의 선택(Decision)과 보상(Reward)을 더한 모델입니다.
MDP (Markov Decision Process)란?
마르코프 속성을 만족하는 환경에서 에이전트가 행동을 통해 상태를 바꾸고, 그 결과로 보상을 받으며 순차적으로 의사결정을 내리는 과정을 수학적으로 모델링한 프레임워크입니다.
즉, 시간이 흐르며 상태가 바뀌는 것을 관찰만 하는 것이 아니라, 에이전트가 직접 행동을 선택해서 더 나은 미래를 만들어가는 문제를 다룹니다.
2.1 상태 (State, $S$)
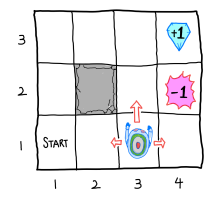
상태는 에이전트가 처할 수 있는 모든 상황의 집합입니다. 아래의 격자 세계(Grid World)를 예로 들면, 에이전트가 위치할 수 있는 각 칸이 하나의 상태가 됩니다.
예를 들어 시작 지점인 (1, 1), 다이아몬드가 있는 (4, 3), 함정이 있는 (4, 2)는 모두 서로 다른 상태입니다. 회색 벽 (2, 2)처럼 들어갈 수 없는 칸은 에이전트가 경험할 수 있는 상태에서 제외됩니다.
2.2 행동 (Action, $A$)
행동은 각 상태에서 에이전트가 선택할 수 있는 움직임의 집합입니다. 격자 세계에서는 위, 아래, 왼쪽, 오른쪽 이동이 행동이 될 수 있습니다.
행동의 결과는 크게 두 방식으로 생각할 수 있습니다.
- 결정론적(Deterministic) 행동: 오른쪽으로 이동하면 100% 확률로 오른쪽 칸으로 이동하는 경우입니다.
- 확률론적(Stochastic) 행동: 오른쪽으로 가려고 했지만 바람이나 미끄러짐 때문에 위나 아래로 밀려날 수 있는 경우입니다.
현실 문제는 대부분 두 번째처럼 불확실성을 포함합니다. 그래서 강화학습에서는 에이전트가 의도한 행동과 실제 결과가 항상 같다고 가정하지 않습니다.
2.3 보상 함수 (Reward Function, $R$)
보상 함수는 에이전트의 목표를 알려주는 점수판입니다. 특정 상태 $s$에서 행동 $a$를 했을 때, 환경이 에이전트에게 주는 즉각적인 피드백을 의미합니다.
격자 세계에서는 보상을 이렇게 설계할 수 있습니다.
- 목표 지점에 도착하면 큰 양의 보상(+1)을 줍니다.
- 함정에 빠지면 큰 음의 보상(-1)을 줍니다.
- 일반 칸으로 이동할 때마다 작은 음의 보상을 줍니다.
마지막 보상은 시간 페널티(Time Penalty) 역할을 합니다. 이 페널티가 있어야 에이전트가 의미 없이 빙빙 돌지 않고, 가능한 한 빨리 목표 지점에 도달하려고 합니다.

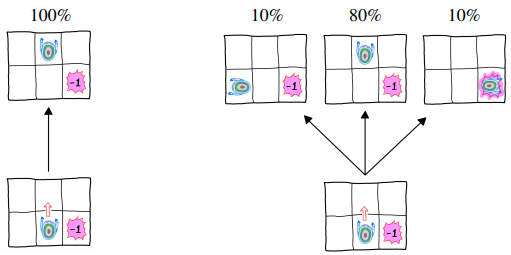
2.4 상태 변환 확률 (State Transition Probability, $P$)
상태 변환 확률은 환경이 어떻게 반응하는지를 나타냅니다. 상태 $s$에서 행동 $a$를 했을 때 다음 상태 $s^{\prime}$로 이동할 확률이며, 보통 $P(s^{\prime} \mid s, a)$로 표기합니다.
바람이 없는 환경이라면 오른쪽 행동을 했을 때 100% 오른쪽 칸으로 이동합니다. 하지만 바람이 있는 환경이라면, 오른쪽으로 가려 했는데도 80% 확률로만 오른쪽에 도착하고 나머지 확률로는 위나 아래로 밀려날 수 있습니다.
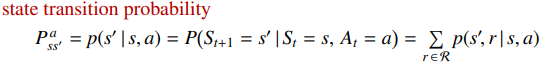
정리하면 MDP는 환경을 이루는 상태($S$), 행동($A$), 보상 함수($R$), 상태 변환 확률($P$)을 바탕으로 순차적 의사결정 문제를 정의합니다. 여기에 미래 보상을 얼마나 중요하게 볼지 정하는 할인율($\gamma$)까지 함께 사용하면, 에이전트가 무엇을 최적화해야 하는지 명확해집니다.
3. MDP의 목표: 최고의 전략(정책)을 찾기
MDP를 정의하는 이유는 결국 하나입니다. 누적 보상을 최대로 만드는 최고의 행동 전략, 즉 최적 정책을 찾기 위해서입니다.
3.1 보상 (Reward) vs. 반환값 (Return)
- 보상 (Reward, $R$): 특정 상태에서 특정 행동을 했을 때 바로 받는 점수입니다.
- 반환값 (Return, $G$): 현재 시점 $t$부터 앞으로 받을 보상들을 할인해서 더한 값입니다.
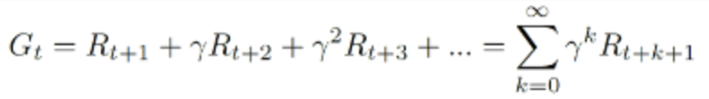
여기서 감마($\gamma$)는 할인율(Discount Factor)입니다. 0과 1 사이의 값을 가지며, 미래 보상을 현재 시점에서 얼마나 중요하게 볼지 정합니다.
$\gamma$가 작으면 에이전트는 가까운 미래의 보상을 더 중요하게 보고, $\gamma$가 1에 가까우면 먼 미래의 보상까지 더 길게 고려합니다. 따라서 강화학습의 목표는 눈앞의 보상 하나를 크게 만드는 것이 아니라, 장기적인 반환값을 최대화하는 것입니다.
3.2 정책 (Policy, $\pi$)
정책은 에이전트의 행동 전략입니다. 특정 상태 $s$에서 어떤 행동 $a$를 선택할지 정하는 규칙이라고 보면 됩니다.
확률적 정책은 다음처럼 표현합니다.
\[\pi(a \mid s)\]이는 상태 $s$에서 행동 $a$를 선택할 확률을 의미합니다.
3.3 가치 함수 (Value Function, V)
가치 함수는 현재 상태나 행동이 장기적으로 얼마나 좋은지를 나타내는 함수입니다. 여기서 “좋다”는 것은 앞으로 얻을 반환값의 기대값이 크다는 뜻입니다.
상태 가치 함수(State-Value Function)는 정책 $\pi$를 따를 때 상태 $s$가 얼마나 좋은지를 나타냅니다.
\[V^\pi(s) = E_\pi[G_t \mid S_t = s]\]행동 가치 함수(Action-Value Function)는 정책 $\pi$를 따를 때 상태 $s$에서 행동 $a$를 선택하는 것이 얼마나 좋은지를 나타냅니다.
\[Q^\pi(s, a) = E_\pi[G_t \mid S_t = s, A_t = a]\]상태 가치 함수가 “이 장소는 좋은가?”에 답한다면, 행동 가치 함수는 “이 장소에서 이 행동을 하는 것은 좋은 선택인가?”에 답합니다.
3.4 최적 정책 (Optimal Policy, $\pi^{\ast}$)
MDP의 최종 목표는 최적 정책을 찾는 것입니다.
최적 정책(Optimal Policy, $\pi^{\ast}$)은 모든 상태에서 가장 큰 장기 보상을 얻도록 행동을 선택하는 정책입니다. 어떤 상태에서 시작하더라도 최적 정책을 따르면 기대 반환값이 최대가 됩니다.
4. 정리하며: 다음 단계로
이번 글에서는 강화학습 문제를 수학적으로 표현하는 기본 틀인 MDP를 정리했습니다.
- 마르코프 속성은 현재 상태만으로 다음 상태를 설명할 수 있다는 가정입니다.
- MDP는 상태, 행동, 보상 함수, 상태 변환 확률로 순차적 의사결정 문제를 정의합니다.
- 에이전트의 목표는 즉각적인 보상이 아니라 장기적인 반환값(Return)을 최대화하는 것입니다.
- 결국 우리가 찾고 싶은 것은 반환값을 최대로 만드는 최적 정책($\pi^{\ast}$)입니다.
그렇다면 최적 정책과 최적 가치 함수는 어떻게 계산할 수 있을까요? 이 질문에 답하기 위해 다음 글에서는 벨만 방정식(Bellman Equation)을 살펴보겠습니다.
