4. RL (Reinforcement Learning)
Unknown MDP에서 경험을 통해 가치를 학습하는 강화학습의 핵심 방법인 GPI, MC, TD, Sarsa, Q-learning, Double Q-learning을 정리한다.
1. 동적 계획법 (DP) vs 강화학습 (RL)
앞 글에서는 Known MDP에서 환경 모델($P$, $R$)을 알고 있을 때, DP로 최적 정책을 계산하는 방법을 봤습니다. 하지만 현실에서는 상태 전이 확률이나 보상 함수를 정확히 모르는 경우가 훨씬 많습니다.
이때 필요한 접근이 강화학습(Reinforcement Learning, RL)입니다. RL은 환경 모델을 모르는 상태에서 에이전트가 직접 경험을 쌓고, 그 경험을 바탕으로 가치 함수나 정책을 학습합니다.
1.1 계산 방식: Full Backup vs Sample Backup
DP와 RL의 가장 큰 차이는 가치를 업데이트할 때 무엇을 사용하는가에 있습니다.
- DP - Full Backup: 환경 모델을 알고 있으므로, 한 상태의 가치를 업데이트할 때 가능한 모든 다음 상태와 보상을 고려합니다.
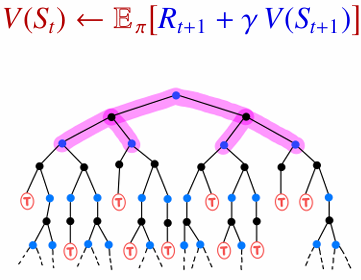
- RL - Sample Backup: 환경 모델을 모르므로, 실제로 경험한 하나의 전이 샘플을 이용해 가치를 업데이트합니다.
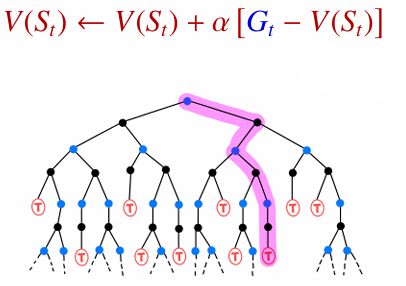
즉, DP는 가능한 경우를 모두 계산하고, RL은 직접 관찰한 샘플로 값을 추정합니다.
1.2 문제 풀이 방식: Solving vs Estimating
최적 정책을 찾는 것은 결국 벨만 최적 방정식의 해를 찾는 문제입니다.
- DP: 상태 전이 확률 $P$와 보상 함수 $R$을 알고 있으므로, 벨만 최적 방정식을 직접 풀어 최적 가치 함수($v^{\ast}$, $q^{\ast}$)를 계산합니다. 이것은 계획(Planning)입니다.
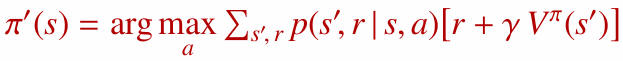
- RL: $P$와 $R$을 모르기 때문에 방정식을 직접 풀 수 없습니다. 대신 환경과 상호작용하며 얻은 경험으로 최적 가치 함수, 특히 $q^{\ast}$를 추정합니다. 이것은 학습(Learning)입니다.
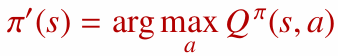
2. 일반화된 정책 반복 (Generalized Policy Iteration, GPI)
일반화된 정책 반복(GPI)은 대부분의 강화학습 알고리즘을 관통하는 기본 구조입니다. 핵심은 정책 평가(Policy Evaluation)와 정책 개선(Policy Improvement)이 서로 영향을 주며 반복된다는 점입니다.
- 정책 평가: 현재 정책 $\pi$를 따랐을 때의 가치 함수($v_\pi$ 또는 $q_\pi$)를 계산하거나 추정합니다.
- 정책 개선: 평가된 가치 함수를 바탕으로 더 높은 가치를 주는 행동을 선택하도록 정책을 업데이트합니다.
2.1 평가와 개선의 상호작용
정책 평가와 정책 개선은 서로를 밀어줍니다.
- 더 나은 정책은 더 좋은 가치 평가의 기준이 됩니다.
- 더 정확한 가치 평가는 더 나은 정책 개선으로 이어집니다.
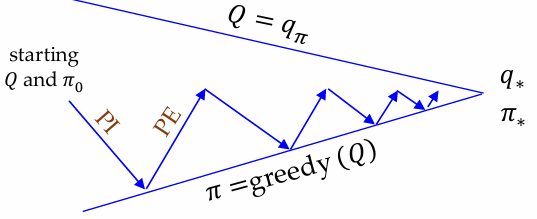
그림에서 정책과 가치 함수는 서로 맞춰지며 점점 안정적인 지점으로 이동합니다. 그 지점이 바로 최적 정책($\pi^{\ast}$)과 최적 가치 함수($v^{\ast}$, $q^{\ast}$)입니다.
2.2 왜 Generalized인가?
GPI가 일반화된 구조라고 불리는 이유는 평가와 개선이 반드시 완벽하게 끝난 뒤 다음 단계로 넘어갈 필요가 없기 때문입니다.
- 정책 반복: 정책 평가를 충분히 끝낸 뒤 정책을 개선합니다.
- 가치 반복: 평가를 한 스텝만 수행하고 개선을 함께 섞습니다.
- 대부분의 RL 알고리즘: 몇 개의 샘플로 가치를 조금 업데이트하고, 바로 정책도 조금 개선합니다.
즉, 많은 강화학습 알고리즘은 GPI를 각자의 방식으로 구현한 것이라고 볼 수 있습니다.
3. 몬테카를로 방법 (Monte Carlo Method, MC)
3.1 몬테카를로 방법이란?
몬테카를로(MC) 방법은 환경 모델 없이 실제 에피소드를 경험하여 가치 함수를 추정하는 방법입니다. DP와 달리 상태 전이 확률을 몰라도 되지만, 하나의 에피소드가 끝난 뒤에야 그 에피소드의 반환값을 계산할 수 있습니다.
MC는 GPI 안에서 정책 평가를 수행하는 한 방법이며, 에피소드 단위의 샘플 기반 다단계 백업을 사용합니다.
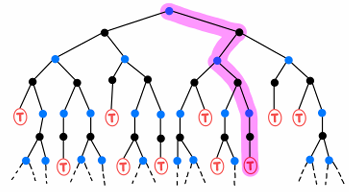
3.2 MC Prediction (Policy Evaluation)
MC의 핵심은 상태-행동 쌍의 가치를 실제 반환값($G_t$)들의 평균으로 추정하는 것입니다.
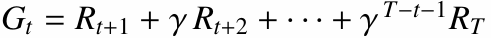
가치 추정은 간단히 말해, 상태 $s$에서 행동 $a$를 했을 때 얻었던 반환값들의 평균으로 $Q(s, a)$를 업데이트하는 방식입니다.
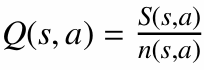
충분히 많은 에피소드를 경험하면 큰 수의 법칙에 따라 추정치 $Q(s, a)$는 실제 가치 $q(s, a)$에 가까워집니다.
- First-Visit MC: 한 에피소드에서 같은 $(s, a)$를 여러 번 방문해도 첫 방문의 반환값만 사용합니다.
- Every-Visit MC: 같은 에피소드 안에서 $(s, a)$를 방문할 때마다 모든 반환값을 사용합니다.
3.3 가치 업데이트 방식: 점진적 평균과 고정 스텝 사이즈
모든 반환값을 저장해두고 매번 평균을 다시 계산하는 것은 비효율적입니다. 그래서 보통 점진적인 업데이트를 사용합니다.
3.3.1 점진적 평균 업데이트 (Incremental Mean)
새로운 반환값 $G_t$를 얻었을 때, 기존 추정값 $Q(S_t, A_t)$를 조금만 수정해서 새로운 평균을 계산합니다.
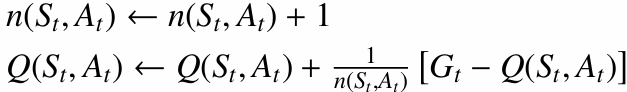
이 방식은 모든 경험에 같은 비중을 둡니다. 환경이 고정되어 있다면 자연스럽지만, 환경이 시간에 따라 바뀌는 경우에는 오래된 경험이 너무 오래 영향을 줄 수 있습니다.
3.3.2 고정 스텝 사이즈 ($\alpha$) 업데이트
실제로는 방문 횟수 기반 평균 대신 고정된 학습률(step-size) $\alpha$를 사용하는 경우도 많습니다.
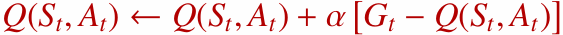
고정 스텝 사이즈를 사용하면 오래된 경험의 영향은 점점 작아지고, 최근 경험에 더 큰 비중을 둘 수 있습니다. 그래서 비정상적(non-stationary) 환경에 더 잘 적응할 수 있습니다.
3.4 Exploitation vs Exploration
강화학습에서는 항상 두 선택 사이의 균형을 잡아야 합니다.
- 활용(Exploitation): 지금까지 알고 있는 정보에서 가장 좋아 보이는 행동을 선택합니다.
- 탐험(Exploration): 더 나은 행동을 찾기 위해 일부러 새로운 행동을 시도합니다.
활용만 하면 지역 최적해에 갇힐 수 있고, 탐험만 하면 단기 보상이 낮아질 수 있습니다. 그래서 두 전략을 적절히 섞어야 합니다.
3.4.1 $\epsilon$-탐욕 (Epsilon-Greedy) 정책
$\epsilon$-탐욕 정책은 가장 기본적인 탐험 전략입니다.
- 확률 $1-\epsilon$로 현재 Q값이 가장 높은 행동을 선택합니다.
- 확률 $\epsilon$로 가능한 행동 중 하나를 무작위로 선택합니다.
학습 초기에는 큰 $\epsilon$으로 탐험을 많이 하고, 시간이 지나며 $\epsilon$을 줄여 활용 비중을 높이는 전략이 자주 사용됩니다.
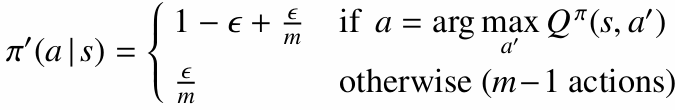
적절한 조건에서 $\epsilon$-greedy 정책은 현재 가치 함수에 대해 정책을 개선하는 방향으로 작동합니다.
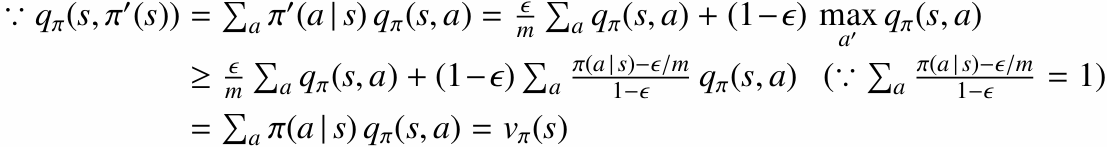
3.4.2 GLIE (Greedy in the Limit with Infinite Exploration)
GLIE는 모든 $(s, a)$를 충분히 많이 탐험하면서도, 시간이 지나면 최종적으로 탐욕 정책에 가까워지는 조건입니다.

$\epsilon$-greedy 정책을 사용하되 $\epsilon \to 0$으로 줄여가면 GLIE 조건을 만족하도록 만들 수 있습니다.
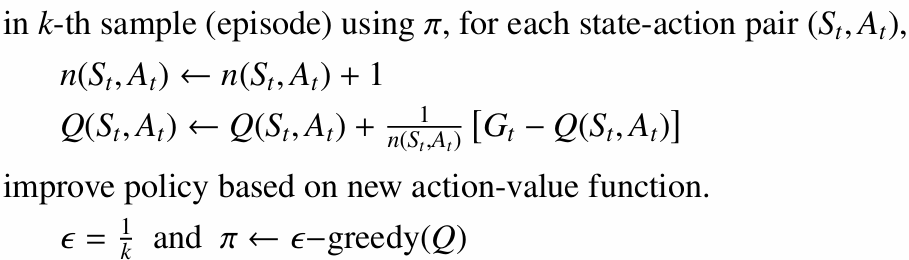
이 조건 아래에서 MC Control은 $Q(s, a)$를 $q^{\ast}(s, a)$에 가깝게 학습할 수 있습니다.
3.5 Monte Carlo Method Pseudo Code

4. TD (Temporal Difference Learning)
4.1 TD 학습이란?
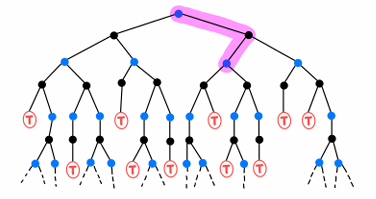
TD(Temporal Difference) 학습은 MC의 샘플 기반 학습과 DP의 부트스트래핑을 결합한 Model-Free 강화학습 방법입니다.
MC는 에피소드가 끝날 때까지 기다린 뒤 실제 반환값으로 업데이트합니다. 반면 TD는 에피소드가 끝나기 전에도, 한 스텝 뒤의 보상과 다음 상태의 추정값을 이용해 바로 업데이트합니다.
- Model-Free: 상태 전이 확률을 몰라도 학습할 수 있습니다.
- Bootstrapping: 완전한 반환값 대신 다음 상태의 추정 가치로 현재 가치를 업데이트합니다.
4.2 On-Policy vs Off-Policy
TD 제어 알고리즘을 이해하려면 목표 정책과 행동 정책의 차이를 알아야 합니다.
4.2.1 목표 정책 (Target Policy)
목표 정책은 에이전트가 최종적으로 학습하고 싶은 정책입니다. 보통 보상을 최대로 만드는 최적 정책($\pi^{\ast}$)을 목표로 합니다.
4.2.2 행동 정책 (Behavior Policy)
행동 정책은 에이전트가 실제로 환경에서 행동을 선택할 때 사용하는 정책입니다. 학습 중에는 탐험이 필요하기 때문에 $\epsilon$-greedy 정책이 행동 정책으로 자주 사용됩니다.
4.2.3 On-Policy: 목표 정책 = 행동 정책
On-Policy 학습에서는 학습하려는 정책과 실제로 행동하는 정책이 같습니다. 에이전트는 현재 따르고 있는 정책의 가치를 배우고, 그 정책을 점진적으로 개선합니다.
- 대표 알고리즘: Sarsa
- 장점: 학습하는 정책과 행동하는 정책이 같아 비교적 안정적입니다.
- 단점: 탐험이 포함된 정책 자체를 학습하므로, 최종 정책이 더 보수적이거나 준최적에 머무를 수 있습니다.
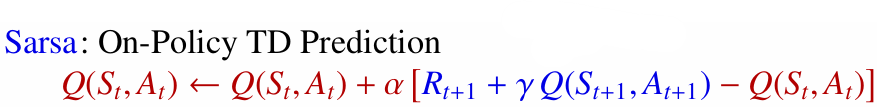

4.2.4 Off-Policy: 목표 정책 $\ne$ 행동 정책
Off-Policy 학습에서는 실제로 행동하는 정책과 학습하려는 정책이 다릅니다. 에이전트는 탐험적인 행동 정책으로 데이터를 모으면서도, 학습은 더 탐욕적인 목표 정책을 기준으로 진행할 수 있습니다.
- 대표 알고리즘: Q-Learning
- 장점: 탐험하면서도 최적 정책($\pi^{\ast}$)을 직접 학습할 수 있고, 다른 정책으로 얻은 경험도 활용하기 쉽습니다.
- 단점: 행동 정책과 목표 정책의 차이가 크면 업데이트 분산이 커져 학습이 불안정해질 수 있습니다.
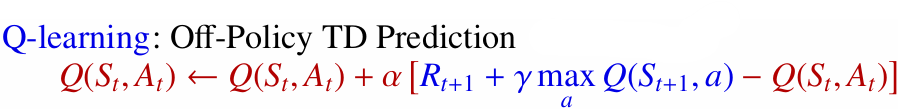

4.2.5 중요도 샘플링 (Importance Sampling)
중요도 샘플링은 행동 정책으로 얻은 데이터를 목표 정책 기준으로 보정할 때 사용하는 방법입니다.


5. Bias vs Variance
5.1 편향 (Bias)과 분산 (Variance)
편향과 분산은 추정이 얼마나 정확하고 안정적인지를 보는 기준입니다.
- 편향(Bias): 추정값의 평균이 실제 값에서 얼마나 벗어나 있는가
- 분산(Variance): 추정값들이 서로 얼마나 크게 흔들리는가
5.2 MC vs TD
5.2.1 MC: 높은 분산, 제로 편향
MC의 업데이트 목표인 반환값($G_t$)은 에피소드가 끝난 뒤 실제로 얻은 보상의 합입니다. 추정치가 섞이지 않은 샘플이므로 편향은 없지만, 에피소드 전체의 무작위성에 영향을 받아 분산이 큽니다.
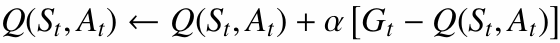
5.2.2 TD: 낮은 분산, 약간의 편향
TD의 업데이트 목표는 다음처럼 현재 추정값 $Q$를 포함합니다.
\[R_{t+1} + \gamma Q(S_{t+1}, A_{t+1})\]추정치를 다시 사용하므로 약간의 편향이 생기지만, 한 스텝 정보만 사용하기 때문에 MC보다 분산은 낮습니다.
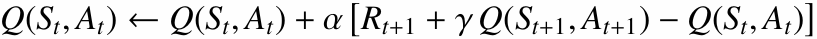
5.2.3 MC vs TD 종합 비교
| 구분 | 몬테카를로 (MC) | 시간차 학습 (TD) |
|---|---|---|
| 편향/분산 | 높은 분산, 제로 편향 | 낮은 분산, 약간의 편향 |
| 업데이트 시점 | 에피소드 종료 후 업데이트 | 매 스텝 업데이트 |
| 업데이트 목표 | 실제 반환값 $G_t$ | TD 타겟 |
| 환경 요구사항 | 종료 환경(Episodic)에 적합 | 종료 및 지속(Continuing) 환경 모두 가능 |
| 초기값 민감도 | 낮음 | 높음 |
| 메모리/계산 | 비교적 많이 필요 | 비교적 적게 필요 |
| 수렴 속도 | 느릴 수 있음 | 실전에서는 보통 더 빠름 |
정리하면, MC는 편향이 없지만 분산이 크고, TD는 약간의 편향이 있지만 분산이 낮습니다. 이 차이가 이후 여러 강화학습 알고리즘의 성격을 나눕니다.
6. Sarsa vs Q-Learning
Sarsa와 Q-Learning의 핵심 차이는 탐험으로 인한 행동의 위험을 가치 평가에 반영하는가입니다.
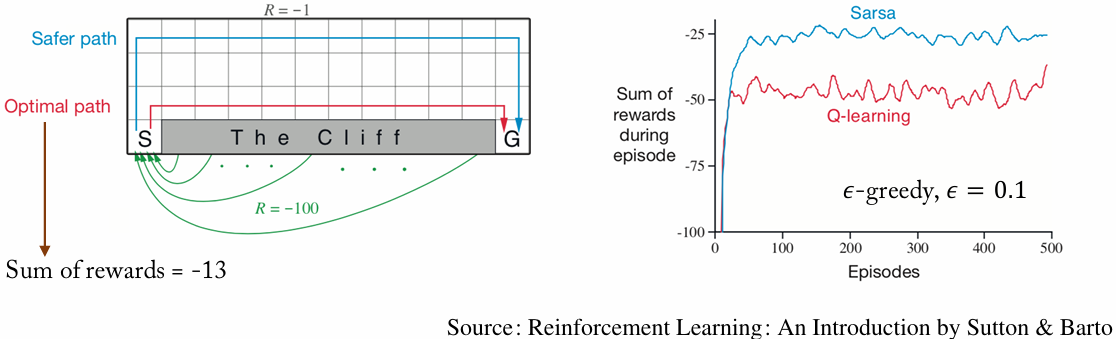
6.1 상황 설정: Cliff Walking
- 목표: 출발점에서 도착점까지 가능한 빨리 이동합니다.
- 위험: 중간에 절벽 구역이 있어 빠지면 큰 페널티를 받고 출발점으로 돌아갑니다.
- 최단 경로: 절벽 바로 위쪽을 따라갑니다.
- 안전 경로: 절벽에서 조금 떨어져 돌아갑니다.
6.2 Sarsa의 접근법
Sarsa는 On-Policy 알고리즘이므로, 실제로 행동하는 $\epsilon$-greedy 정책의 가치를 학습합니다.
탐험 때문에 절벽 근처에서 잘못 움직일 가능성이 있다면, 그 위험까지 가치에 반영됩니다. 그래서 Sarsa는 이론상 최단 경로보다 조금 돌아가더라도 더 안전한 경로를 선호할 수 있습니다.
6.3 Q-Learning의 접근법
Q-Learning은 Off-Policy 알고리즘이므로, 실제 탐험 행동과 별개로 항상 다음 상태에서 최적 행동을 선택한다고 가정하고 업데이트합니다.
그 결과 Q-Learning은 절벽 바로 위의 최단 경로를 높은 가치로 학습하기 쉽습니다. 다만 학습 중에는 여전히 $\epsilon$-greedy로 행동하므로, 탐험 때문에 실제로 절벽에 빠지는 일이 생길 수 있습니다.
6.4 한눈에 보는 요약
| 구분 | Sarsa | Q-Learning |
|---|---|---|
| 학습 방식 | On-Policy | Off-Policy |
| 업데이트 기준 | 실제 다음 행동 | 가능한 최적 다음 행동 |
| 탐험의 영향 | 가치에 반영됨 | 목표 가치에는 덜 반영됨 |
| 경로 성향 | 더 안전한 경로 선호 | 더 빠른 최적 경로 선호 |
6.5 Expected Sarsa
Expected Sarsa는 다음 행동 하나를 샘플링하는 대신, 다음 상태에서 가능한 행동들의 Q값을 확률로 가중평균하여 업데이트하는 TD 알고리즘입니다.
기존 Sarsa는 다음 상태 $S^{\prime}$에서 실제로 선택된 행동 $A^{\prime}$의 값 $Q(S^{\prime}, A^{\prime})$를 사용합니다. 반면 Expected Sarsa는 가능한 모든 행동의 기대값을 사용하므로 업데이트 분산을 줄일 수 있습니다.

| 구분 | Sarsa | Expected Sarsa | Q-Learning |
|---|---|---|---|
| 업데이트 목표 | $Q(S^{\prime}, A^{\prime})$ | $\mathbb{E}[Q(S^{\prime}, A^{\prime})]$ | $\max_{a^{\prime}} Q(S^{\prime}, a^{\prime})$ |
| 분산 | 높음 | 낮음 | 낮음 |
| 학습 방식 | On-Policy | 주로 On-Policy | Off-Policy |
| 계산 복잡도 | 낮음 | 높음 | 낮음 |
7. Double Q-Learning
7.1 Q-Learning의 문제점: 최대화 편향 (Maximization Bias)
Q-Learning의 업데이트에는 max 연산이 들어갑니다.
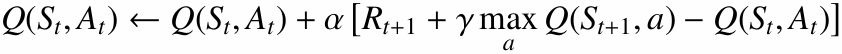
학습 초기에는 Q값 추정치가 부정확합니다. 이때 max 연산은 우연히 높게 추정된 행동을 선택할 가능성이 큽니다. 이 과정이 반복되면 Q값을 실제보다 과대평가할 수 있는데, 이를 최대화 편향(Maximization Bias)이라고 합니다.
7.2 Double Q-Learning의 해결책
Double Q-Learning은 이 문제를 줄이기 위해 두 개의 Q함수, $Q_A$와 $Q_B$를 사용합니다. 핵심은 행동 선택과 가치 평가를 분리하는 것입니다.
- 행동 선택: 다음 상태 $S^{\prime}$에서 어떤 행동이 가장 좋아 보이는지 하나의 Q함수로 선택합니다.
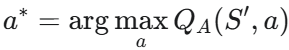
- 가치 평가: 선택된 행동 $a^{\ast}$의 가치를 다른 Q함수로 평가합니다.
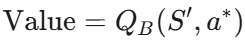
예를 들어 $Q_A$가 행동을 선택했다면 $Q_B$가 그 행동의 가치를 평가합니다. 다음에는 역할을 바꿔 $Q_B$가 선택하고 $Q_A$가 평가할 수 있습니다.
이렇게 하면 하나의 Q함수가 우연히 어떤 행동을 과대평가하더라도, 독립적인 다른 Q함수가 그 값을 평가하므로 과대평가 편향을 줄일 수 있습니다.
7.3 최종 요약
- Double Q-Learning은 Q-Learning의 max 연산에서 생기는 과대평가 문제를 줄이기 위한 방법입니다.
- 두 Q함수로 행동 선택과 가치 평가를 나누어 학습을 더 안정적으로 만듭니다.

8. 정리하며: 다음 단계로
이번 글에서는 환경 모델을 모르는 Unknown MDP에서 경험을 통해 학습하는 강화학습 방법들을 정리했습니다.
- RL은 환경 모델 없이 샘플 경험으로 가치를 추정합니다.
- GPI는 정책 평가와 정책 개선이 상호작용하는 큰 틀입니다.
- MC는 에피소드가 끝난 뒤 실제 반환값으로 학습합니다.
- TD는 한 스텝 뒤의 보상과 추정값으로 바로 학습합니다.
- Sarsa는 On-Policy, Q-Learning은 Off-Policy의 대표 알고리즘입니다.
- Double Q-Learning은 Q-Learning의 과대평가 편향을 줄입니다.
다음 글에서는 이런 강화학습 아이디어를 신경망과 결합한 Deep Reinforcement Learning (DRL)로 넘어가겠습니다.