5. DRL (Deep Reinforcement Learning)
DQN 계열 알고리즘과 Policy Gradient, REINFORCE, Actor-Critic, A3C, A2C의 핵심 아이디어를 정리한다.
1. Reinforcement Learning vs Deep Reinforcement Learning
앞 글에서는 환경 모델을 모르는 Unknown MDP에서 경험을 통해 가치를 학습하는 방법을 정리했습니다. 하지만 상태 공간이 커지면 Q-table 방식은 곧 한계에 부딪힙니다.
예를 들어 이미지, 로봇 센서값, 자율주행 상태처럼 입력 차원이 큰 문제에서는 모든 상태-행동 쌍을 표로 저장할 수 없습니다. 이때 필요한 것이 Deep Reinforcement Learning (DRL)입니다.
DRL은 Q-table 대신 신경망(Neural Network)을 사용해 Q함수, 가치 함수, 정책을 근사합니다.
- 기존 RL: 상태-행동 값을 주로 테이블 형태로 저장합니다.
- DRL: 신경망이 복잡한 상태 입력을 받아 가치나 정책을 출력합니다.
이 덕분에 DRL은 Atari 게임, 로봇 제어, 자율주행처럼 고차원 입력을 다루는 문제에 적용될 수 있습니다.
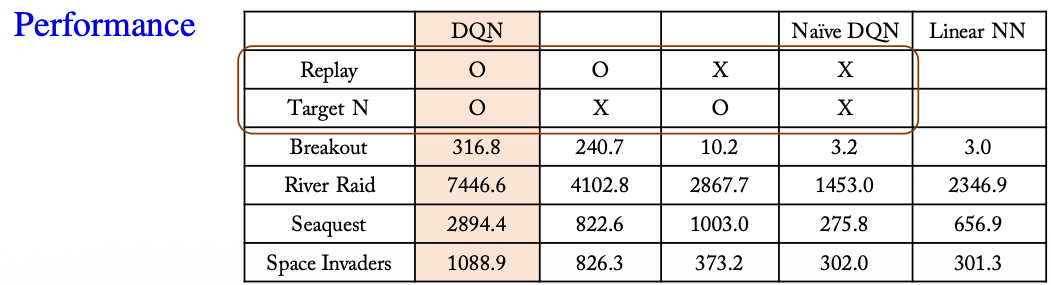
2. Naive DQN
Naive DQN은 Q-Learning에 심층 신경망을 단순히 결합한 형태입니다. Q-table 대신 신경망이 Q함수 $Q(s, a; \theta)$를 근사합니다.
이미지 기반 게임에서는 CNN이 화면 픽셀을 입력으로 받아 각 행동의 Q값을 예측합니다. 하지만 Q-Learning을 신경망에 그대로 붙이면 학습이 매우 불안정해집니다.
2.1 Naive DQN의 문제점
Naive DQN의 핵심 문제는 두 가지입니다.
- 샘플 간 시간적 상관성: 에이전트가 연속해서 얻는 경험들은 서로 강하게 연결되어 있습니다. 이를 그대로 학습하면 딥러닝이 가정하는 i.i.d. 데이터 조건이 깨져 학습이 불안정해집니다.
- 비정상적인 타겟: Q-Learning의 타겟에도 같은 신경망이 사용됩니다. 파라미터 $\theta$가 업데이트될 때마다 타겟값도 계속 바뀌므로, 모델이 따라가야 할 목표가 흔들립니다.

3. DQN
DQN(Deep Q-Network)은 Naive DQN의 불안정성을 줄이기 위해 두 가지 핵심 장치를 도입했습니다.
- 경험 리플레이(Experience Replay)
- 타겟 네트워크(Target Network)
이 두 가지가 DQN의 학습을 안정화하는 핵심입니다.
3.1 경험 리플레이 (Experience Replay)
경험 리플레이는 에이전트가 얻은 경험 $(s_t, a_t, r_{t+1}, s_{t+1})$을 리플레이 버퍼에 저장했다가, 학습할 때 무작위 미니배치로 꺼내 쓰는 방법입니다.

경험 리플레이는 다음 문제를 완화합니다.
- 상관성 감소: 연속된 경험을 그대로 쓰지 않고 무작위로 샘플링하므로 샘플 간 상관성이 줄어듭니다.
- 데이터 효율 증가: 한 번 얻은 경험을 여러 번 재사용할 수 있습니다.
- 희귀 경험 보존: 중요한 경험이 바로 사라지지 않고 버퍼에 남아 다시 학습에 사용될 수 있습니다.
동작 과정
- 에이전트가 현재 상태 $s_t$에서 $\epsilon$-greedy 정책으로 행동 $a_t$를 선택합니다.
- 환경에서 보상 $r_{t+1}$과 다음 상태 $s_{t+1}$을 관찰합니다.
- 경험 $(s_t, a_t, r_{t+1}, s_{t+1})$을 리플레이 버퍼에 저장합니다.
- 학습 시 버퍼에서 무작위 미니배치를 샘플링해 Q-network를 업데이트합니다.
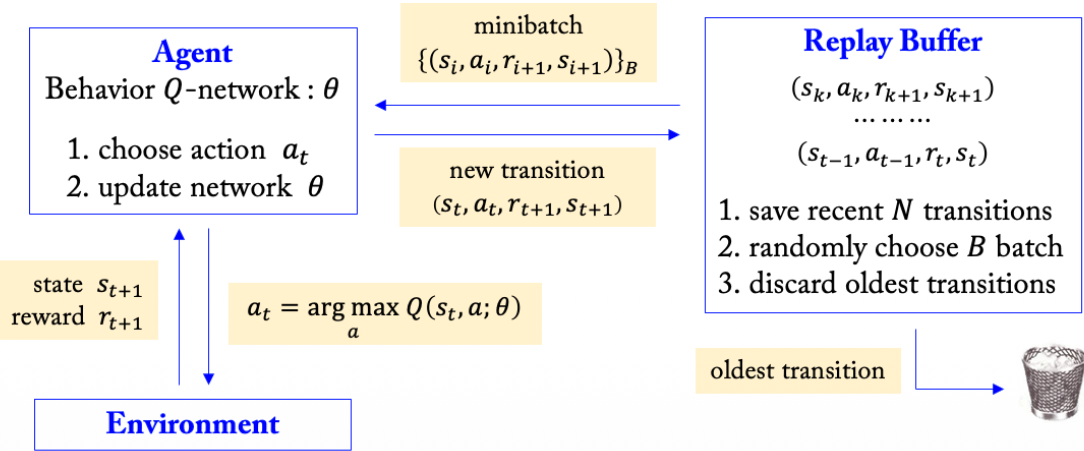
3.2 타겟 네트워크 (Target Network)
타겟 네트워크는 Q-Learning 타겟이 계속 바뀌는 문제를 줄이기 위해 사용됩니다.
DQN은 두 네트워크를 둡니다.
- Online Q-network: 현재 Q값을 예측하고 매 학습 단계마다 업데이트됩니다.
- Target Q-network: 타겟값 계산에 사용되며, 일정 주기마다 Online Q-network의 파라미터를 복사합니다.
타겟 네트워크를 천천히 업데이트하면 학습 목표가 급격히 흔들리지 않아 더 안정적으로 학습할 수 있습니다.
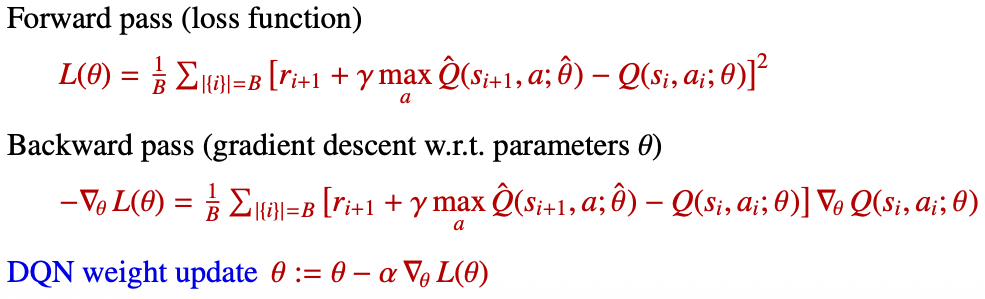
3.3 DQN Pseudo Code

3.4 DQN의 CNN 활용
DQN은 Atari 게임처럼 이미지 상태를 입력으로 받을 수 있습니다.
- 과거 여러 프레임을 쌓아 움직임 정보를 포함합니다.
- CNN이 픽셀 이미지를 압축해 상태 특징을 추출합니다.
- 작은 위치 변화가 중요하기 때문에 DQN은 보통 max pooling 대신 stride convolution으로 해상도를 줄입니다.
3.5 Multi-Step Learning
기본 DQN은 한 스텝 보상과 다음 상태의 추정값으로 타겟을 만듭니다. Multi-step learning은 $n$-step return을 사용해 더 긴 미래의 실제 보상 정보를 함께 반영합니다.
3.5.1 $n$-step return
$n$-step return은 현재 시점부터 $n$스텝 동안 받은 보상을 할인해 더하고, 마지막 상태의 추정 가치를 더한 값입니다.
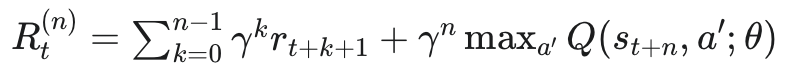
이 방식은 한 스텝보다 더 많은 실제 보상 정보를 사용하므로, 적절한 $n$을 선택하면 학습 속도와 데이터 효율을 높일 수 있습니다.
3.5.2 DQN에 적용
Multi-step target을 사용하면 DQN의 손실 함수도 다음처럼 바뀝니다.
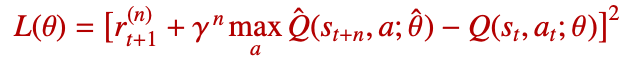
여기서 $\hat{\theta}$는 타겟 네트워크의 파라미터입니다. 즉, DQN의 안정화 장치인 타겟 네트워크는 Multi-step learning에서도 그대로 중요합니다.
4. Double DQN
Double DQN은 DQN의 과대평가 편향(overestimation bias)을 줄이기 위해 나온 방법입니다.
일반적인 Q-Learning은 다음 상태의 가치를 계산할 때 max 연산을 사용합니다. 추정치에 노이즈가 있으면 max 연산은 우연히 높게 추정된 값을 고르기 쉽고, 이 과정이 반복되면 Q값이 실제보다 과대평가될 수 있습니다.
4.1 Double Q-Learning과 Double DQN
Double Q-Learning의 핵심은 행동 선택과 가치 평가를 분리하는 것입니다.
DQN에서는 기본 손실이 다음과 같이 구성됩니다.
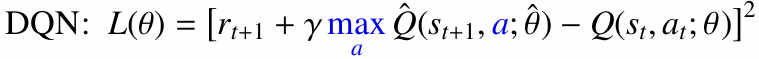
Double DQN은 다음 행동을 선택할 때는 Online Q-network를 사용하고, 그 행동의 가치를 평가할 때는 Target Q-network를 사용합니다.
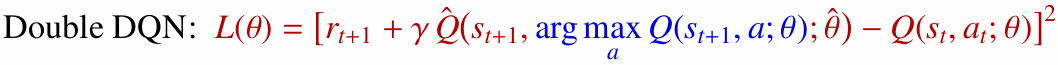
이렇게 하면 하나의 네트워크가 우연히 높은 값을 선택하더라도, 다른 네트워크가 평가를 담당하므로 과대평가 편향을 줄일 수 있습니다.
4.2 Prioritized Replay
Prioritized Replay는 리플레이 버퍼에서 모든 경험을 균일하게 샘플링하지 않고, 더 많이 배울 수 있는 경험을 더 자주 뽑는 방법입니다.
일반적으로 우선순위는 TD error를 기준으로 둡니다. TD error가 큰 경험은 현재 예측이 많이 틀렸다는 뜻이므로, 학습할 정보가 많다고 볼 수 있습니다.
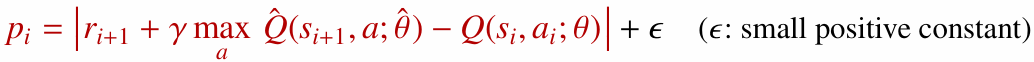
여기서 $\epsilon$은 우선순위가 0이 되는 것을 막기 위해 더하는 작은 값입니다.
다만 우선순위가 높은 경험만 계속 뽑으면 데이터 분포가 치우칩니다. 이를 보정하기 위해 중요도 샘플링 가중치(Importance Sampling Weight)를 사용합니다.

$\alpha$는 우선순위를 얼마나 강하게 반영할지, $\beta$는 편향을 얼마나 보정할지 조절합니다.
4.3 Double DQN with Prioritized Replay Pseudo Code

5. Dueling DQN
Dueling DQN은 Q값을 바로 예측하지 않고, 상태 가치와 행동의 상대적 이점을 나누어 학습하는 구조입니다.
5.1 Dueling DQN의 구조
Dueling DQN은 앞부분의 CNN 인코더를 공유한 뒤, 마지막에 두 스트림으로 나뉩니다.
- Value stream: 현재 상태의 가치 $V(s)$를 추정합니다.
- Advantage stream: 각 행동이 현재 상태에서 얼마나 더 좋은지 $A(s, a)$를 추정합니다.
두 값을 합쳐 최종 Q값 $Q(s, a)$를 만듭니다.
5.2 핵심 아이디어
어떤 상태에서는 행동에 따른 차이가 크지 않을 수 있습니다. 예를 들어 게임 화면에서 당장 피해야 할 장애물이 없다면, 여러 행동의 결과가 비슷할 수 있습니다.
Dueling DQN은 이런 경우에도 상태 자체의 가치 $V(s)$를 효율적으로 학습할 수 있습니다. 모든 행동의 Q값을 따로따로 완전히 학습하기보다, 상태 가치와 행동별 이점을 분리해서 더 안정적으로 학습하는 것입니다.
5.3 Identifiability Issue (식별성 문제)
단순히 $Q(s, a) = V(s) + A(s, a)$로 두 값을 더하면 문제가 생깁니다. 같은 Q값을 만드는 $V$와 $A$의 조합이 무수히 많기 때문입니다.
예를 들어 $V(s)$에 상수 $c$를 더하고 $A(s, a)$에서 $c$를 빼도 합은 같습니다. 그래서 $V$와 $A$가 각각 의미 있는 값으로 학습되지 않을 수 있습니다.
이를 해결하기 위해 advantage에서 최댓값 또는 평균값을 빼는 방식을 사용합니다.
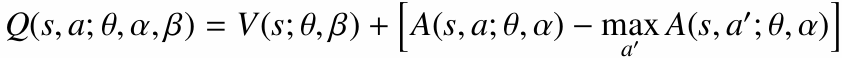
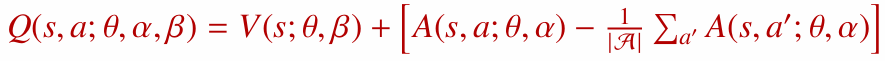
5.4 Dueling DQN의 구현
Dueling DQN은 네트워크 마지막 부분만 바꾸면 됩니다.
- $V(s)$ stream은 상태당 하나의 스칼라 값을 출력합니다.
- $A(s, a)$ stream은 행동 개수만큼의 값을 출력합니다.
- 두 출력은 aggregator를 통해 Q값으로 합쳐지고, 전체 네트워크는 역전파로 함께 학습됩니다.
6. Policy Gradient (정책 경사)
DQN 계열은 Q값을 학습한 뒤, 그 값을 기준으로 행동을 선택합니다. 반면 Policy Gradient는 정책 $\pi(a \mid s; \theta)$ 자체를 직접 학습합니다.
이 방식은 특히 연속 행동 공간에서 유용합니다. 행동이 연속적이면 모든 행동의 Q값을 비교하기 어렵지만, 정책 네트워크가 바로 행동 분포를 출력하면 더 자연스럽게 제어할 수 있습니다.
6.1 Policy Gradient Theorem
정책의 목표 함수 $J(\theta)$는 정책이 만들어내는 기대 반환값입니다.
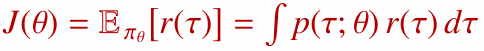
정책 파라미터 $\theta$는 경사 상승법으로 업데이트합니다.
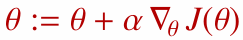
정책 경사 정리는 이 기울기를 샘플 궤적(trajectory)으로 추정할 수 있게 해줍니다.
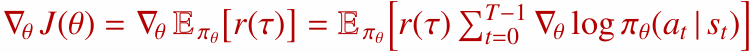
핵심은 환경의 동역학 $p(s_{t+1} \mid s_t, a_t)$를 직접 알 필요가 없다는 점입니다. 에이전트가 직접 궤적을 샘플링하고, 그 궤적의 보상과 로그 정책 확률의 기울기를 이용해 정책을 업데이트할 수 있습니다.
7. REINFORCE
REINFORCE는 Monte Carlo 방식으로 Policy Gradient를 구현한 대표적인 알고리즘입니다.

REINFORCE는 실제 에피소드를 끝까지 실행한 뒤, 그 반환값을 이용해 정책을 업데이트합니다. 구조는 단순하지만, 궤적 샘플에 따라 업데이트의 분산이 커질 수 있습니다.
7.1 REINFORCE with Baseline
분산을 줄이기 위해 기준선(baseline) $b(s_t)$를 도입할 수 있습니다.
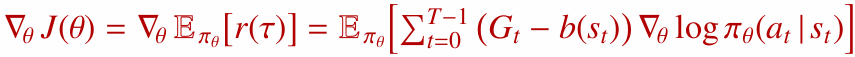
기준선은 행동과 무관한 함수라면 정책 경사의 기댓값을 바꾸지 않습니다. 즉, 편향을 추가하지 않으면서 분산을 줄일 수 있습니다.
대표적인 기준선은 상태 가치 함수 $V(s)$입니다.

7.2 DQN vs Policy Gradient
DQN과 Policy Gradient의 차이는 다음처럼 정리할 수 있습니다.
- DQN: Q함수를 학습하고, 가장 큰 Q값을 주는 행동을 선택합니다.
- Policy Gradient: 정책 자체를 학습하고, 정책이 출력한 분포에 따라 행동을 선택합니다.
- DQN: 이산 행동 공간에서 강력합니다.
- Policy Gradient: 연속 행동 공간이나 확률적 정책이 필요한 문제에 자연스럽습니다.
8. Actor-Critic
Actor-Critic은 Policy Gradient의 높은 분산 문제를 줄이기 위해 정책을 담당하는 Actor와 가치를 평가하는 Critic을 함께 사용하는 구조입니다.
- Actor: 정책 $\pi(a \mid s)$를 출력하고, 어떤 행동을 할지 결정합니다.
- Critic: 가치 함수 $V(s)$ 또는 $Q(s, a)$를 추정하고, Actor의 행동이 얼마나 좋았는지 평가합니다.
8.1 Actor-Critic의 장점
- 분산 감소: Critic의 가치 추정을 사용해 REINFORCE보다 안정적으로 정책을 업데이트할 수 있습니다.
- 온라인 학습: 에피소드가 끝날 때까지 기다리지 않고 TD 방식으로 매 스텝 업데이트할 수 있습니다.
- 학습 속도 향상: 더 자주, 더 안정적으로 업데이트할 수 있어 학습이 빨라질 수 있습니다.
8.2 Actor-Critic의 역할
Critic은 현재 가치 추정과 타겟의 차이를 줄이는 방향으로 학습합니다.
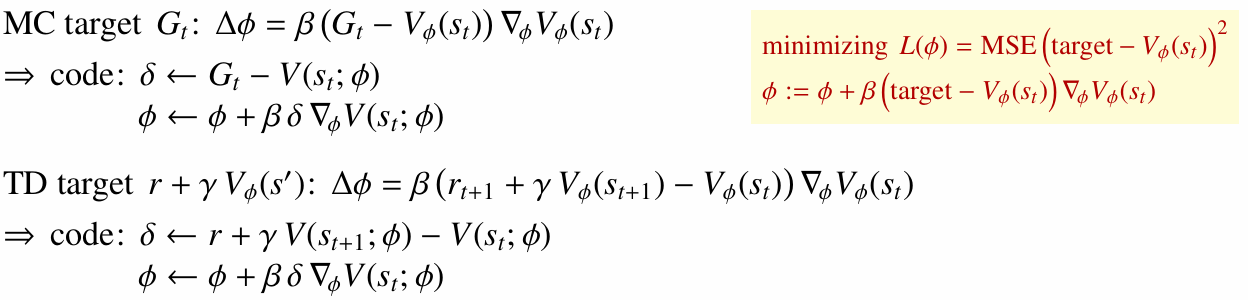
Actor는 Critic이 제공한 평가를 이용해 정책 파라미터를 업데이트합니다.
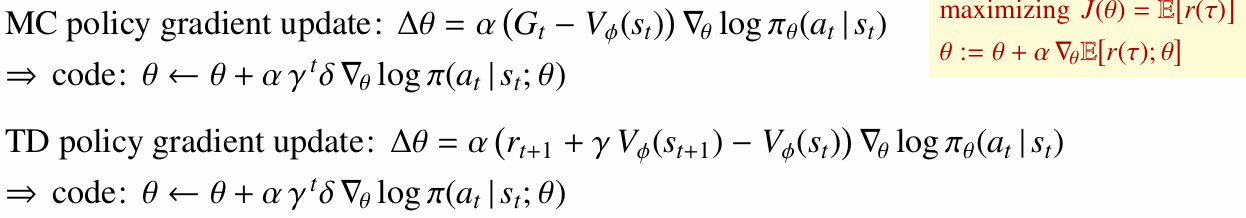
8.3 다양한 Policy Gradient 형태
Policy Gradient는 여러 형태로 표현될 수 있고, 어떤 값을 Critic으로 쓰느냐에 따라 다양한 Actor-Critic 알고리즘으로 이어집니다.

8.4 Actor-Critic 알고리즘의 일반적인 흐름
- Actor와 Critic 네트워크를 초기화합니다.
- Actor가 현재 정책에 따라 행동을 선택합니다.
- 환경에서 보상 $r$과 다음 상태 $s^{\prime}$를 얻습니다.
- Critic이 TD error를 계산하고 가치 함수를 업데이트합니다.
- Actor가 Critic의 평가를 바탕으로 정책을 업데이트합니다.
- 다음 상태로 이동해 이 과정을 반복합니다.

9. A3C (Asynchronous Advantage Actor-Critic)
A3C는 Actor-Critic에 비동기 병렬 학습을 결합한 알고리즘입니다. 여러 worker가 각자 환경을 실행하며 경험을 모으고, 글로벌 네트워크를 비동기적으로 업데이트합니다.
9.1 A3C의 구조와 작동 방식
- Global Network: 모든 worker가 공유하는 Actor-Critic 네트워크입니다.
- Worker Agents: 각 worker는 자신만의 환경 복사본에서 경험을 수집합니다.
- 비동기 업데이트: worker들은 서로를 기다리지 않고, 각자 계산한 기울기로 글로벌 네트워크를 업데이트합니다.
9.2 A3C의 주요 장점
- 경험의 비상관화: 여러 worker가 서로 다른 환경 상태에서 경험을 수집하므로 경험 간 상관성이 줄어듭니다.
- Experience Replay 불필요: 병렬 worker가 다양한 데이터를 만들기 때문에 DQN처럼 큰 리플레이 버퍼가 꼭 필요하지 않습니다.
- CPU 친화적: 여러 스레드에서 병렬로 실행할 수 있어 멀티코어 CPU에서도 효율적입니다.
9.3 Advantage Function의 활용
A3C는 advantage를 사용합니다. Advantage $A(s, a)$는 특정 행동이 현재 상태에서 평균적인 기대보다 얼마나 더 좋거나 나빴는지를 나타냅니다.
A3C는 advantage를 계산할 때 Q값을 직접 추정하기보다, $n$-step return을 사용합니다.
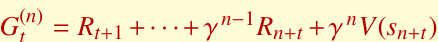
이 값은 여러 스텝의 실제 보상과 마지막 상태의 가치 추정을 함께 사용하므로, 편향과 분산 사이의 균형을 잡는 데 도움이 됩니다.

10. A2C (Advantage Actor-Critic)
A2C는 A3C의 동기식 버전입니다. A3C가 worker들이 각자 비동기적으로 업데이트하는 방식이라면, A2C는 worker들의 경험을 모아 한 번에 동기식 업데이트를 수행합니다.
10.1 동기식 업데이트의 필요성
A3C에서는 worker마다 다른 시점의 파라미터로 학습할 수 있습니다. 이런 비동기성은 빠르지만, 업데이트 방향이 조금 불안정해질 수 있습니다.
10.2 A2C의 해결책
A2C는 모든 worker가 일정 스텝 동안 경험을 모을 때까지 기다립니다. 이후 각 worker의 기울기를 모아 하나의 큰 배치처럼 업데이트합니다.
- 모든 worker가 같은 최신 파라미터에서 출발합니다.
- 업데이트가 동기적으로 이루어져 학습이 더 일관적입니다.
- 큰 배치 연산을 사용할 수 있어 GPU 활용에 유리합니다.
10.3 A2C의 장점
- 학습 안정성: 동기식 업데이트 덕분에 기울기 방향이 더 일관됩니다.
- GPU 효율: 여러 worker의 데이터를 묶어 배치 연산으로 처리하기 좋습니다.
- 구현 단순성: 실제 구현에서는 A3C보다 A2C가 더 다루기 쉬운 경우가 많습니다.
정리하면 A3C는 비동기 병렬성으로 다양한 경험을 빠르게 모으고, A2C는 동기식 업데이트로 안정성과 GPU 효율을 챙기는 방식입니다.
11. 정리하며: 다음 단계로
이번 글에서는 강화학습을 신경망과 결합한 DRL의 주요 흐름을 정리했습니다.
- DQN은 Q-Learning에 신경망을 결합하고, 경험 리플레이와 타겟 네트워크로 학습을 안정화합니다.
- Double DQN은 Q값 과대평가 문제를 줄입니다.
- Prioritized Replay는 더 많이 배울 수 있는 경험을 더 자주 샘플링합니다.
- Dueling DQN은 상태 가치와 행동 어드밴티지를 분리해 학습합니다.
- Policy Gradient는 정책을 직접 최적화합니다.
- Actor-Critic은 Actor와 Critic을 함께 사용해 Policy Gradient의 분산을 줄입니다.
- A3C와 A2C는 Actor-Critic을 병렬 학습 구조로 확장한 방법입니다.
다음 글에서는 Policy Gradient 계열을 더 깊게 들어가서 DDPG, TRPO, Natural Policy Gradient, PPO를 살펴보겠습니다.