6. Policy Gradient DRL
Policy Gradient 계열의 대표 알고리즘인 DDPG, TRPO, Natural Policy Gradient, PPO의 핵심 아이디어와 발전 흐름을 정리한다.
1. DDPG (Deep Deterministic Policy Gradient)
앞 글에서 DQN 계열은 Q값을 학습하고, Policy Gradient 계열은 정책을 직접 학습한다고 정리했습니다. DDPG는 이 두 흐름을 연결하는 알고리즘입니다.
DDPG는 연속적인 행동 공간을 다루기 위해 DQN의 안정화 기법과 Actor-Critic 기반 Policy Gradient를 결합합니다.
1.1 DDPG가 해결하려는 문제
DQN은 이산 행동 공간에서는 강력하지만, 행동이 연속적이면 그대로 사용하기 어렵습니다. 가능한 행동을 잘게 나누어 이산화할 수도 있지만, 행동 차원이 커질수록 경우의 수가 폭발합니다.
반면 일반적인 Policy Gradient는 확률적 정책 $\pi(a \mid s)$를 학습합니다. 이 방식은 탐험이 자연스럽지만, 기울기 추정의 분산이 크고 많은 샘플이 필요할 수 있습니다.
DDPG는 여기서 결정적 정책(Deterministic Policy)을 사용합니다.
\[a = \mu(s)\]즉, 상태 $s$가 주어지면 Actor가 하나의 행동을 직접 출력합니다.
1.2 DDPG의 핵심 아이디어
DDPG는 다음 구성 요소로 이루어집니다.
- Actor Network: 결정적 정책 $\mu(s; \theta)$를 학습하고, 상태 $s$에서 행동 $a$를 출력합니다.
- Critic Network: 행동 가치 함수 $Q(s, a; \phi)$를 학습하고, Actor의 행동을 평가합니다.
- Target Actor / Target Critic: DQN의 Target Network처럼 천천히 업데이트되는 안정화용 네트워크입니다.
- Experience Replay: DQN처럼 리플레이 버퍼에서 미니배치를 샘플링해 학습합니다.
학습 과정은 간단히 말해, Critic은 Actor의 행동이 얼마나 좋은지 평가하고, Actor는 Critic이 더 높은 Q값을 주는 방향으로 업데이트됩니다.

1.3 DPG와 SPG의 차이
확률적 정책 경사(SPG)와 결정적 정책 경사(DPG)의 차이는 다음과 같습니다.
| 특징 | 확률적 정책 경사 (Stochastic PG) | 결정적 정책 경사 (Deterministic PG) |
|---|---|---|
| 정책 | $\pi(a \vert s)$ | $\mu_\theta(s)$ |
| 업데이트 | $Q^\pi(s, a)\nabla_\theta \log \pi_\theta(a \vert s)$ | $\nabla_\theta \mu_\theta(s)\nabla_a Q^\mu(s, a)$ |
| 샘플링 | 상태-행동 쌍 $(s, a)$에서 샘플링 | 상태 $s$에서 샘플링 |
| 특징 | 탐험이 정책 안에 포함됨 | 샘플 효율성이 좋음 |
결정적 정책 경사는 행동까지 샘플링하지 않고 상태에 대해 기울기를 계산하므로 샘플 효율성이 좋습니다. DDPG는 이 장점 덕분에 로봇 제어처럼 연속 행동을 다루는 문제에 자주 사용됩니다.
2. TRPO (Trust Region Policy Optimization)
DDPG는 연속 행동 공간을 다룰 수 있지만, 정책 업데이트의 크기를 잘 조절해야 합니다. 스텝이 너무 크면 성능이 크게 무너질 수 있고, 너무 작으면 학습이 느립니다.
TRPO는 이 문제를 정책을 너무 멀리 바꾸지 않는 업데이트로 해결하려고 합니다. 핵심은 정책 업데이트에 신뢰 영역(Trust Region)을 두는 것입니다.
2.1 TRPO의 주요 개념
TRPO는 기대 반환을 최대화하되, 새 정책이 이전 정책에서 너무 멀어지지 않도록 KL divergence 제약을 둡니다.
직관적으로는 다음과 같습니다.
- 정책을 개선하고 싶다.
- 하지만 한 번에 너무 크게 바꾸면 위험하다.
- 그러니 이전 정책과의 차이가 일정 범위 안에 있을 때만 업데이트하자.
이런 방식은 학습률을 직접 튜닝하는 부담을 줄이고, 정책 성능이 갑자기 무너지는 문제를 완화합니다.
2.2 DRL 목표
강화학습의 목표는 정책 $\pi$의 기대 반환 $\eta(\pi)$를 최대화하는 것입니다.
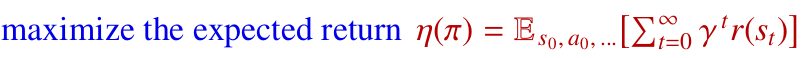
2.3 성능 차이 관점
새 정책 $\pi$의 성능은 이전 정책 $\pi_{\mathrm{old}}$와 advantage 함수 $A^{\pi_{\mathrm{old}}}$를 이용해 표현할 수 있습니다.
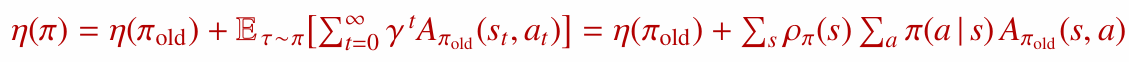
여기에는 상태 방문 빈도 $\rho^\pi(s)$가 들어갑니다.
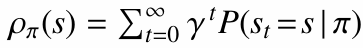
정리하면 정책 성능 차이는 다음처럼 볼 수 있습니다.
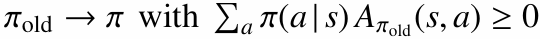
문제는 $\rho^\pi(s)$가 새 정책 $\pi$에 복잡하게 의존한다는 점입니다. 그래서 이 식을 그대로 최적화하기 어렵습니다.
2.4 국소적 근사
TRPO는 상태 방문 빈도의 변화를 잠시 무시하고, $\rho^\pi$ 대신 이전 정책의 방문 빈도 $\rho^{\pi_{\mathrm{old}}}$를 사용합니다. 이렇게 하면 현재 정책 근처에서만 유효한 국소적 근사 함수 $L_{\pi_{\mathrm{old}}}$를 얻을 수 있습니다.

이 근사는 작은 업데이트에서는 실제 목적 함수와 잘 맞습니다. 하지만 여전히 중요한 질문이 남습니다.
얼마나 작은 업데이트가 안전한가?
2.5 보수적 정책 반복 (Conservative Policy Iteration)
보수적 정책 반복은 새 정책으로 바로 갈아타지 않고, 이전 정책과 새 정책 후보를 섞는 방식입니다.
\[\pi(a \mid s) = (1-\alpha)\pi_{\mathrm{old}}(a \mid s) + \alpha \pi^{\prime}(a \mid s)\]이 혼합 정책에 대해 정책 성능 개선의 하한을 만들 수 있습니다.
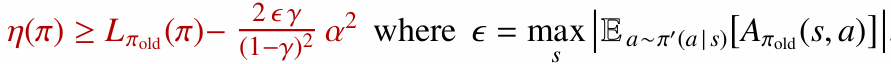
다만 이 하한은 혼합 정책에 대한 결과라서, 일반적인 신경망 정책 업데이트에 바로 쓰기에는 한계가 있습니다.
2.6 일반적인 확률적 정책으로 확장
TRPO는 이 하한을 일반적인 확률적 정책으로 확장합니다. 핵심은 정책 사이의 차이를 전체 변동 거리(Total Variation Distance)로 다루고, 다시 KL divergence로 바꾸는 것입니다.
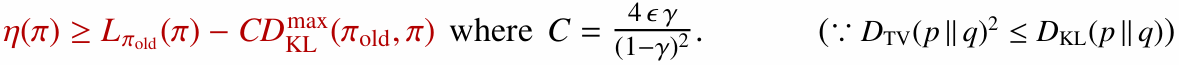
이 과정을 거치면 정책 성능을 보장하기 위해 KL divergence를 제한해야 한다는 아이디어가 자연스럽게 나옵니다.
2.7 소수화-최대화 (Minorization-Maximization, MM)
MM 알고리즘은 어려운 목적 함수를 직접 최적화하지 않고, 현재 위치에서의 하한 함수(lower bound)를 만든 뒤 그 하한을 최대화하는 방법입니다.
- 현재 정책 근처에서 실제 목적 함수의 하한을 만듭니다.
- 그 하한을 최대화해 다음 정책을 찾습니다.
- 새 정책에서 다시 하한을 만들고 반복합니다.

TRPO는 이 관점에서, 실제 성능이 나빠지지 않도록 보수적인 하한을 최적화하는 알고리즘으로 볼 수 있습니다.
2.8 신뢰 영역 (Trust Region) 제약
TRPO의 핵심 최적화 문제는 다음과 같이 이해할 수 있습니다.
- 국소 목적 함수 $L_{\theta_{\mathrm{old}}}(\theta)$를 최대화한다.
- 단, 새 정책과 이전 정책의 KL divergence가 너무 커지지 않도록 제한한다.
이론적으로는 모든 상태에서 KL divergence의 최댓값을 제한하는 것이 이상적입니다. 하지만 실제로 모든 상태를 확인하는 것은 불가능합니다.
2.9 실용적 근사와 몬테카를로 추정
그래서 실용적인 TRPO는 두 가지 근사를 사용합니다.
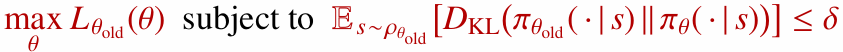
- 모든 상태의 최대 KL 대신, 샘플 상태들에 대한 평균 KL을 사용합니다.
- 기대값은 몬테카를로 샘플 평균으로 근사합니다.
또한 이전 정책에서 모은 샘플을 새 정책 기준으로 재사용하기 위해 importance sampling을 사용합니다.

2.10 최종 최적화 문제
결국 TRPO는 다음 형태의 문제를 풉니다.
- 이전 정책에서 모은 샘플로 surrogate objective를 최대화한다.
- 평균 KL divergence가 신뢰 영역 크기 $\delta$를 넘지 않도록 제한한다.
이렇게 하면 정책이 크게 흔들리지 않으면서도 성능을 개선할 수 있습니다.
2.11 TRPO의 실용적 알고리즘
실제로 TRPO는 다음 과정을 반복합니다.
- 현재 정책으로 데이터를 수집합니다.
- advantage 또는 Q값을 추정합니다.
- surrogate objective와 KL 제약을 구성합니다.
- Natural Policy Gradient, Conjugate Gradient, Line Search를 이용해 제약을 만족하는 업데이트를 찾습니다.
2.12 TRPO의 단점
TRPO는 안정적이지만 구현과 계산이 무겁습니다. 특히 Conjugate Gradient와 Line Search가 필요하고, 큰 신경망에서는 계산 비용이 커집니다.
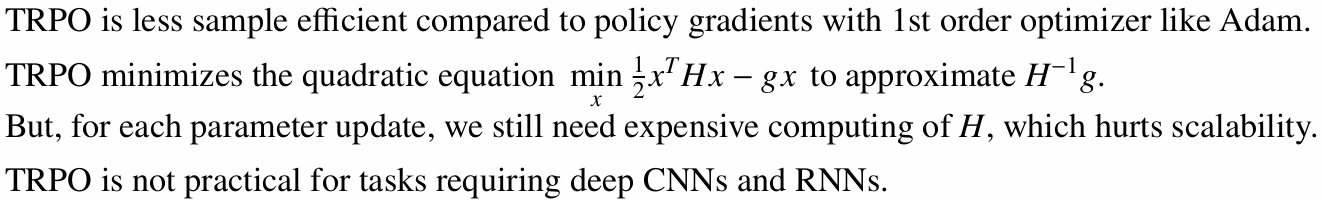
3. 자연 정책 경사 (Natural Policy Gradient, NPG)
TRPO의 제약 최적화 문제는 다음과 같은 형태로 볼 수 있습니다.
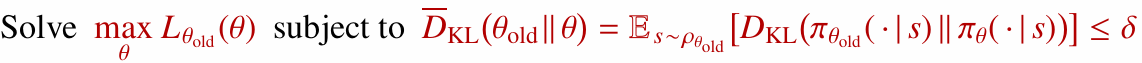
NPG는 이 문제를 근사적으로 풀기 위한 방법입니다.
3.1 1차/2차 근사
목적 함수 $L_{\theta_{\mathrm{old}}}(\theta)$는 1차 테일러 근사로 다룹니다.
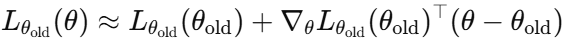
KL divergence 제약은 2차 테일러 근사로 다룹니다.
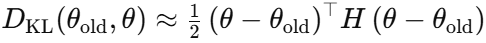
그러면 원래의 최적화 문제는 다음과 같은 2차 제약 문제로 바뀝니다.
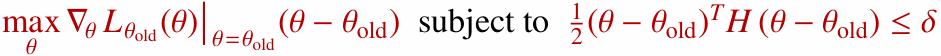
여기서 $H$는 Fisher Information Matrix입니다. 이는 파라미터 변화가 정책 분포를 얼마나 바꾸는지 나타내는 곡률 정보로 볼 수 있습니다.
3.2 자연 경사 (Natural Gradient)
일반적인 경사는 파라미터 공간에서 가장 가파른 방향을 따릅니다. 하지만 정책에서는 파라미터 변화량보다 정책 분포가 얼마나 변했는지가 더 중요합니다.
자연 경사는 Fisher 정보 행렬을 이용해 정책 공간의 거리 구조를 반영한 업데이트 방향입니다.
\[H^{-1}\nabla_\theta L_{\theta_{\mathrm{old}}}\]즉, 단순히 파라미터를 크게 바꾸는 방향이 아니라, 정책 분포의 변화까지 고려해 더 자연스러운 방향으로 업데이트합니다.
3.3 TRPO에서의 실용적 계산
문제는 $H^{-1}$를 직접 계산하기 어렵다는 점입니다. 딥러닝 모델은 파라미터 수가 많기 때문에 행렬 역행렬 계산이 매우 비쌉니다.
TRPO는 이를 직접 계산하는 대신 선형 방정식 형태로 바꿉니다.
\[Hx = g\]여기서 $g$는 정책 경사입니다. 이 식을 Conjugate Gradient로 풀고, Line Search로 KL 제약을 만족하는 스텝 크기를 찾습니다.

정리하면 NPG는 정책 공간의 곡률을 반영한 업데이트 방향이고, TRPO는 이를 신뢰 영역 제약과 함께 실용적으로 구현한 알고리즘입니다.
4. Proximal Policy Optimization (PPO)
TRPO는 안정적이지만 구현이 복잡합니다. PPO는 TRPO의 핵심 아이디어인 정책을 너무 크게 바꾸지 말자를 훨씬 단순한 목적 함수로 구현합니다.
TRPO의 기본 목적은 다음과 같은 신뢰 영역 최적화입니다.
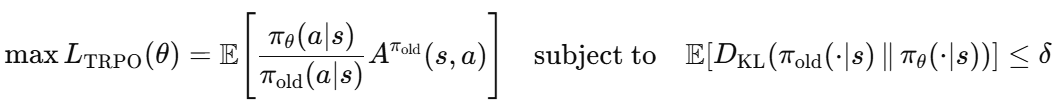
PPO는 KL 제약을 직접 풀지 않고, 정책 비율(policy ratio)을 사용합니다.
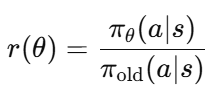
이 비율은 새 정책이 이전 정책에 비해 특정 행동을 얼마나 더 자주 선택하려 하는지 나타냅니다.
4.1 Clipped Surrogate Objective
PPO의 핵심은 policy ratio가 너무 커지거나 작아지는 것을 잘라내는 clipped objective입니다.
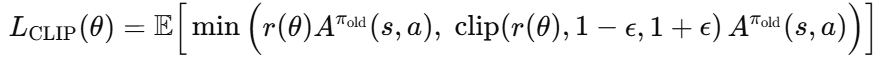
clip 연산은 정책이 한 번에 너무 크게 변하는 것을 막습니다. Advantage가 양수일 때는 좋은 행동의 확률을 너무 과하게 높이지 못하게 하고, advantage가 음수일 때는 나쁜 행동의 확률을 너무 과하게 낮추지 못하게 합니다.

이 방식은 TRPO처럼 복잡한 제약 최적화를 풀지 않아도, 단순한 gradient 기반 학습으로 안정적인 정책 업데이트를 가능하게 합니다.

4.2 PPO의 의미
PPO는 TRPO보다 이론적 보장은 약하지만, 구현이 훨씬 쉽고 계산 비용이 낮습니다. 그래서 실제 DRL 실험과 응용에서 매우 널리 사용됩니다.
5. 주요 발전 흐름
Policy Gradient 계열의 흐름은 다음처럼 정리할 수 있습니다.
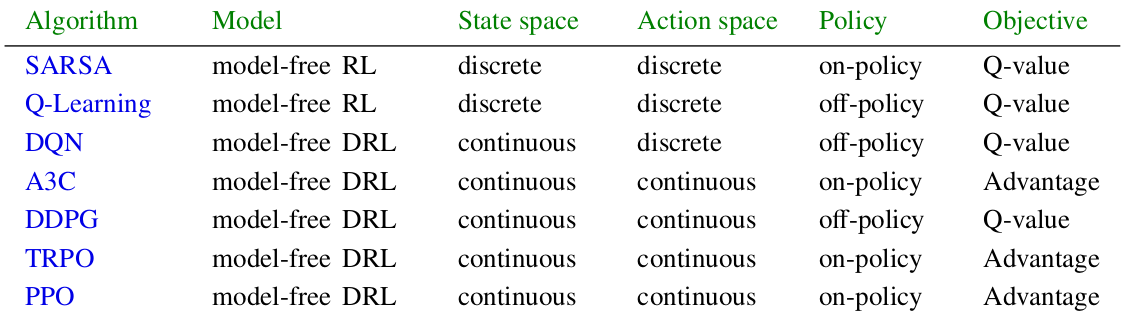
- DQN: Q함수 근사와 안정화 기법을 통해 고차원 상태 입력을 다루는 기반을 만들었습니다.
- DDPG: DQN의 안정화 기법과 deterministic actor를 결합해 연속 행동 공간을 다루었습니다.
- TRPO: KL divergence 기반 trust region으로 정책 업데이트를 안정화했습니다.
- NPG: 정책 공간의 곡률을 반영한 자연 경사 방향을 사용합니다.
- PPO: TRPO의 복잡한 제약 최적화를 clipped objective로 단순화했습니다.
6. 정리하며
이번 글에서는 Policy Gradient 계열 DRL 알고리즘의 발전 흐름을 정리했습니다.
- DDPG는 deterministic actor와 critic을 사용해 연속 행동 공간을 다룹니다.
- TRPO는 정책이 한 번에 너무 크게 변하지 않도록 trust region을 둡니다.
- NPG는 정책 공간의 곡률을 고려한 자연 경사를 사용합니다.
- PPO는 clipped objective로 TRPO의 안정성을 더 단순하게 구현합니다.
여기까지 보면 가치 기반 방법(DQN 계열)과 정책 기반 방법(Policy Gradient 계열)의 큰 흐름이 어느 정도 연결됩니다. 이후에는 이 알고리즘들을 실제 환경과 구현 코드에서 어떻게 다루는지로 넘어가면 좋습니다.